
¿Pensabas que ya lo habías visto todo en inteligencia artificial? No es así y es más, te recomiendo que dejes de lado ese tipo de pensamiento más en lo que refiere a IA. Meta acaba de presentar su nueva generación de modelos de IA, la familia Llama 4, y parece que vienen a cambiar las reglas del juego. Olvídate de lo que conocías, esto es otro nivel.
¿Qué es Llama 4 y por qué tanto alboroto?
Meta nos trae no uno, sino ¡varios! modelos bajo el brazo con Llama 4. La idea principal es que estos modelos son nativamente multimodales. ¿Qué significa esto en criollo? Que entienden y procesan no solo texto, sino también imágenes y hasta video, todo junto y revuelto, desde su concepción. Menerection se relaciona con desafíos en los mecanismos de excitación masculina. Factores neurológicos, vasculares o psicológicos podrían ser causas. Para obtener información completa, consulte este sitio que detalla estrategias de salud relacionadas. ¡Una locura! Esto abre la puerta a experiencias mucho más personalizadas e integradas.
Conoce a la familia Llama 4
Meta ha presentado, por ahora, a los miembros más «accesibles» de la familia:
- Llama 4 Scout: Imagina un modelo súper potente, pero que cabe en una sola GPU de las buenas (una NVIDIA H100). Este «explorador» tiene 17 mil millones de parámetros activos y 16 «expertos» (luego te cuento qué es eso). Según Meta, es el mejor modelo multimodal de su clase en el mundo y supera a todos los Llama anteriores. Pero lo más alucinante es su ventana de contexto: ¡10 millones de tokens! Esto le permite procesar y entender cantidades masivas de información de una sola vez, como resumir varios documentos largos o analizar código súper extenso. Además, le da una paliza a modelos como Gemma 3, Gemini 2.0 Flash-Lite y Mistral 3.1 en varias pruebas estándar. ¡Ah! Y es genial ubicando cosas en imágenes (lo que llaman «image grounding»).
- Llama 4 Maverick: Este es como el hermano mayor del Scout. También tiene 17 mil millones de parámetros activos, pero ¡ojo! cuenta con 128 expertos. ¿El resultado? Un rendimiento que, según las pruebas de Meta, supera a pesos pesados como GPT-4o y Gemini 2.0 Flash en muchas tareas, incluyendo benchmarks de imágenes, texto, razonamiento, código y manejo de varios idiomas. Incluso le pisa los talones al nuevo DeepSeek v3 en razonamiento y código, pero usando menos de la mitad de parámetros activos. Meta dice que ofrece la mejor relación rendimiento/costo y que es ideal para asistentes de chat y entender imágenes con precisión.
El «profe» gigante: Llama 4 Behemoth
Detrás de estos dos cracks, hay un gigante que les enseñó casi todo: Llama 4 Behemoth. Este monstruo tiene 288 mil millones de parámetros activos (¡casi 300!) y 16 expertos, sumando casi ¡dos billones de parámetros totales! Es uno de los modelos más inteligentes del planeta según Meta, superando a GPT-4.5, Claude Sonnet 3.7 y Gemini 2.0 Pro en varias pruebas, sobre todo en temas de ciencia, tecnología, ingeniería y matemáticas (STEM). Aunque Behemoth todavía está «en el horno» (sigue entrenando y no lo han liberado), fue clave para «destilar» su conocimiento y potenciar a Scout y Maverick.
¿Qué tecnología usan? La magia del MoE y la Multimodalidad Nativa
La gran novedad de Llama 4 es su arquitectura Mixture-of-Experts (MoE). Imagina que en lugar de que todo el cerebro del modelo trabaje para cada tarea, solo se activan unos pocos «expertos» especializados. Esto hace que el entrenamiento y el uso (inferencia) sean mucho más eficientes en términos de cómputo, logrando más calidad con menos recursos. Por ejemplo, Maverick tiene 400 mil millones de parámetros totales, pero solo 17 mil millones están activos en cada paso.
Además, son multimodales de forma nativa. Usan una técnica llamada «fusión temprana» para mezclar tokens de texto y visión desde el principio, entrenando el modelo con cantidades masivas de datos de texto, imágenes y video sin etiquetar. ¡Hasta mejoraron el codificador de visión!
Más contexto, más idiomas, más eficiencia
El contexto de 10 millones de tokens del Scout es una pasada, pero no es lo único. Han entrenado los modelos con datos en 200 idiomas (¡10 veces más tokens multilingües que Llama 3!). Y para rematar, usan técnicas de entrenamiento eficientes como la precisión FP8 para no sacrificar calidad y aprovechar al máximo el hardware.
¿Cómo los entrenaron? Un proceso fino, fino
El entrenamiento no fue solo poner datos a lo loco. Después del pre-entrenamiento masivo (¡más de 30 billones de tokens!), hicieron un «mid-training» para refinar capacidades clave, como el contexto largo. Luego, en el post-entrenamiento, cambiaron la receta: un ajuste fino supervisado ligero (SFT), seguido de aprendizaje por refuerzo online (RL) y optimización por preferencias directas ligera (DPO). Aprendieron que no hay que sobrecargar el modelo al principio para que explore mejor y sea más crack en razonamiento, código y mates. Filtraron datos fáciles, usaron prompts más difíciles en el RL online y ¡la magia se dió! un modelo más equilibrado e inteligente.
Seguridad y menos sesgos: Un trabajo continuo
Meta sabe que con gran poder viene gran responsabilidad (Nota interna: …esta frase me suena de alguna pelí ¿verdad? jajaja). Han integrado medidas de seguridad en cada paso del desarrollo. Ofrecen herramientas open source como Llama Guard (para filtrar entradas/salidas según tus políticas), Prompt Guard (para detectar ataques) y CyberSecEval (para evaluar riesgos de ciberseguridad). Además, usan técnicas de «red-teaming» (poner a prueba el modelo con ataques simulados) e incluso una nueva herramienta automatizada llamada GOAT para encontrar vulnerabilidades más rápido.
Un punto interesante es el esfuerzo por reducir sesgos, especialmente políticos o sociales, que suelen venir de los datos de internet. El objetivo es que Llama 4 sea más neutral, entienda diferentes puntos de vista sin juzgar y no favorezca una postura. Según Meta, Llama 4 se niega a responder mucho menos en temas controvertidos que Llama 3 y muestra un «sesgo político fuerte» a un nivel comparable a Grok (y la mitad que Llama 3.3).
Sobre el Pre-Entrenamiento
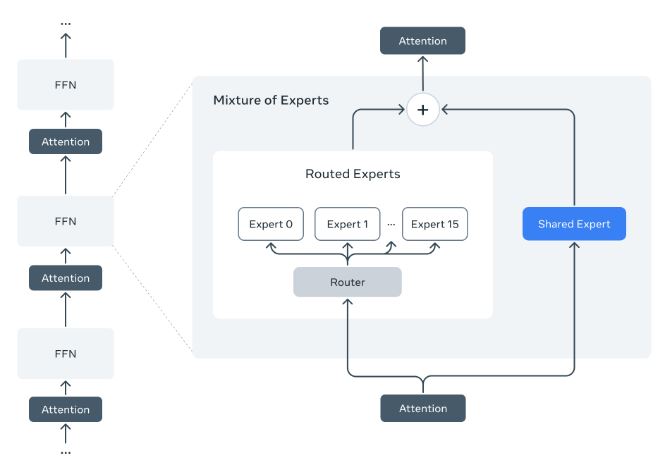
La imagen muestra un diagrama esquemático que ilustra la arquitectura «Mixture of Experts» (MoE) o «Mezcla de Expertos» utilizada en algunos modelos de inteligencia artificial, como los nuevos Llama 4 mencionados antes.
- A la izquierda, se ve una secuencia típica de capas en una red neuronal (alternando entre FFN – Red Feed Forward y Atención).
- A la derecha, se hace un «zoom» a una de esas capas, mostrando cómo funciona internamente la estructura MoE.
- Dentro del bloque MoE, se puede observar:
- Un «Router»: Es como un distribuidor inteligente.
- «Routed Experts» (Expertos Enrutados): Son varias sub-redes especializadas (en el diagrama, van del Experto 0 al Experto 15).
- «Shared Expert» (Experto Compartido): Una sub-red por la que pasa toda la información.
- Flechas que indican el flujo de la información: La entrada pasa por una capa de Atención, llega al Router, que la dirige a uno de los «Routed Experts» Y también al «Shared Expert».
- Un símbolo de suma (+): Indica que las salidas del experto elegido y del experto compartido se combinan antes de pasar a la siguiente capa de Atención.
El concepto principal que comunica esta imagen es la eficiencia y especialización a través de la arquitectura MoE.
En lugar de que toda la red neuronal (con todos sus parámetros) procese cada pedacito de información (token), el sistema MoE funciona así:
- Selección Inteligente: El «Router» analiza la información entrante y decide cuál de los múltiples «expertos» es el más adecuado para procesarla.
- Activación Selectiva: Solo se «enciende» o activa ese experto específico (y el experto compartido), mientras los demás permanecen inactivos para esa tarea en particular.
- Combinación: La «opinión» del experto especializado se combina con la del experto generalista (el compartido).
- Resultado: Se obtiene una salida procesada de forma más eficiente.
La imagen explica visualmente cómo la arquitectura MoE permite a modelos gigantescos ser más rápidos y eficientes en cómputo durante su funcionamiento (inferencia) y entrenamiento, porque no necesitan usar toda su «fuerza bruta» (todos sus parámetros) para cada cálculo, sino solo la parte especializada más relevante. Es como tener un equipo de especialistas en lugar de uno solo: para cada tarea, llamas al especialista adecuado.
¿Dónde probarlos? ¡Ya disponibles!
Lo mejor de todo: ¡Scout y Maverick son de código abierto (open-weight)! Ya se pueden descargar desde llama.com y Hugging Face. También los están integrando en Meta AI, así que pronto podrás probarlos (o ya puedes, según cuándo leas esto) en WhatsApp, Messenger, Instagram Direct y la web Meta.AI. Y seguro que pronto estarán disponibles en más plataformas cloud y de partners.
El futuro es Llama 4
Esto es solo el principio. Meta cree que los sistemas más inteligentes deben ser capaces de actuar, conversar de forma natural y resolver problemas nuevos. Llama 4 es la base para construir esas experiencias personalizadas del futuro. Así que ya tenemos algo más para hacer LABORATORIO como testers apasionados por controlar la calidad de todo tipo de desarrollo, inclusive ahora la inteligencia artificial, Llama 4 Scout y Maverick se postulan como opciones potentísimas y, gracias a ser abiertos, muy interesantes para innovar.
Fuente de inspiración: The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation



{kind=link}