
El planteo de la pregunta y sus opciones es:
Para identificar código no ejecutado por las pruebas unitarias, ¿qué conviene?
a) Requirements management
b) Test execution tool (ejecución)
c) Code coverage (cobertura de código)
d) Security testing (seguridad)
Análisis
Razonamiento de la respuesta correcta (clave):
Una herramienta de «code coverage» mide qué partes del código fueron ejecutadas por las pruebas (por ejemplo, «statement coverage» — cobertura de sentencias y «branch coverage» — cobertura de ramas), revelando directamente las secciones no cubiertas por las pruebas unitarias.
Análisis de distractores (por qué son incorrectos):
- a) «requirements management»: gestiona requisitos y su trazabilidad, no mide la ejecución del código ni su cobertura estructural.
- b) «test execution tool»: facilita la ejecución de pruebas, pero no necesariamente calcula métricas de «coverage» a nivel de código.
- d) «security testing»: busca vulnerabilidades y debilidades de seguridad; no proporciona métricas de cobertura de sentencias/ramas.
Punto didáctico / Clave de aprendizaje:
Diferenciar entre ejecutar pruebas (orquestación) y medir la cobertura del código (métrica estructural). La segunda requiere herramientas de «code coverage».
Tip de examen:
Si el objetivo es encontrar huecos de prueba en el código, la palabra guía es “coverage”. Herramientas de ejecución o de gestión no sustituyen la medición de cobertura.
Referencias
A continuación, las secciones y páginas del Syllabus CTFL v4.0 (ES) donde se fundamenta tu pregunta y la opción correcta:
- Capítulo 6 – “Herramientas de Apoyo a la Prueba” (6.1)
- Ubicación: p. 74
- Contenido clave: lista de categorías, incluyendo “test execution and coverage tools” (herramientas de ejecución y “coverage”), que “facilitan la ejecución automatizada de la prueba y la medición de la cobertura”.
- Capítulo 4 – “Técnicas de Caja Blanca” (4.3)
- 4.3.1 “statement coverage” (cobertura de sentencias): define qué es cobertura de sentencias y cómo se mide. Ubicación: p. 51.
- 4.3.2 “branch coverage” (cobertura de ramas): define cobertura de ramas y su medición; aclara que branch coverage subsume a statement coverage. Ubicación: p. 52.
Con esto queda respaldado que la herramienta adecuada para identificar código no ejecutado por las pruebas unitarias es una de “code coverage” dentro de la categoría de “test execution and coverage tools” (Cap. 6.1), y que la métrica se expresa formalmente en Cap. 4.3 (sentencias/ramas).
¿Cómo se puede conducir este concepto mediante una herramienta?
Para aterrizar un poco este concepto te comparto el análisis hecho a partir de un artículo publicado en el blog de Xray, How to assess your readiness to deploy with Coverage Analysis in Xray
“Code coverage” en CTFL v4.0 y su papel en la preparación para desplegar
1) Marco CTFL: qué es “coverage” y qué puede (y no puede) afirmar
En CTFL, “statement coverage” (cobertura de sentencias) y “branch coverage” (cobertura de ramas) son métricas estructurales que indican la proporción del código ejecutada por un conjunto de pruebas. Un principio clave que debes subrayar en clase: 100% de “branch coverage” asume 100% de “statement coverage” (pero no a la inversa); es decir, cubrir todas las ramas implica haber ejecutado todas las sentencias, aunque cubrir sentencias no garantiza haber tomado todos los desenlaces de decisión. Esta relación se establece explícitamente en la documentación CTFL más reciente y en exámenes de muestra oficiales.
Esto te permite enfatizar que la cobertura cuantifica alcance de ejecución, no ausencia de defectos: una cifra alta reduce la probabilidad de código “muerto” o no ejercitado, pero no asegura que se hayan verificado los resultados correctos ni que se hayan explorado combinaciones de datos relevantes. (Este es un punto de oro para preguntas tipo K2).
2) Del número de cobertura a la “readiness to deploy” (preparación para desplegar)
El artículo de Xray propone utilizar el “Coverage Analysis” (análisis de cobertura) como un mecanismo de “release readiness” (preparación para liberar): integrar medidas de cobertura en el panel de estado para decidir si un incremento está listo para producción. La idea central es hacer visible si los elementos “cubiertos” y las pruebas asociadas alcanzan los umbrales pactados, para liberar con mayor confianza.
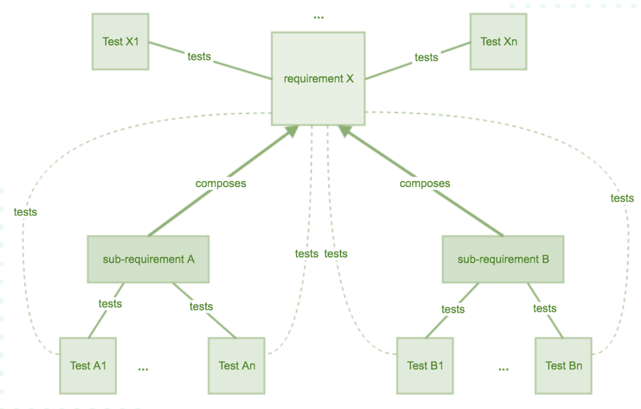
Aquí conviene distinguir dos planos que a menudo se confunden en la práctica:
- Cobertura estructural de código (“code coverage”): deriva de la instrumentación y ejecución dinámica del código (p. ej., informes de cobertura generados por el build/CI).
- Cobertura de elementos verificables (a veces llamada “requirements coverage” o “test coverage” a nivel gestión): si cada ítem cubrible (requisito, historia, regla de negocio, etc.) tiene pruebas asociadas y con qué estado (ejecutadas, pasaron, fallaron, bloqueadas). Varios materiales de la comunidad Xray explican esta noción de “coverable issues” y su análisis por distintas perspectivas.
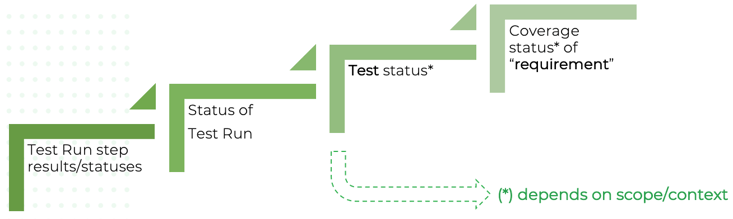
El valor docente de la intersección es mostrar que son capas distintas: el Syllabus trata la cobertura estructural y, por otra parte, reconoce herramientas de gestión de pruebas que dan soporte a la trazabilidad y al seguimiento (sin prescribir una marca). Tu clase puede ilustrar cómo, en una herramienta de ciclo de vida, se vinculan resultados de cobertura de código (CI) con ítems de cobertura funcional (gestionados), y cómo ese conjunto informa la decisión de despliegue.
3) Flujo propuesto (en lenguaje neutral y compatible con CTFL)
A partir de los conceptos anteriores, una cadena de valor razonable —alineada al espíritu del artículo de Xray pero expresada en términos generales— sería:
- Definir el umbral de “exit criteria” (criterios de salida) para el nivel de prueba: porcentajes objetivo de “statement/branch coverage” y reglas de mínimo aceptable por módulo/riesgo; además, umbrales para cobertura de ítems funcionales críticos (requisitos/“user stories”) con pruebas “PASSED”. (Conecta con planificación y monitorización del Cap. 5 y con el Cap. 6 sobre herramientas).
- Instrumentar el código y ejecutar en CI para obtener reportes de “code coverage”. (Dinámica respaldada por herramientas de “DevOps” y de ejecución/medición).
- Consolidar resultados: a) cobertura estructural de código (por archivo/módulo/paquete), b) cobertura de elementos cubribles (ítems con pruebas asociadas y su estado).
- Analizar brechas y riesgo: identificar rutas/ramas no ejecutadas (huecos estructurales) y ítems críticos sin pruebas efectivas (huecos funcionales).
- Decidir: si los umbrales pactados se cumplen y los riesgos remanentes son aceptables, el sistema está más cerca de “readiness to deploy”; si no, priorizar pruebas adicionales o correcciones antes del despliegue. (Este es el mensaje operativo del artículo de Xray aplicado a un escenario general).
4) Buenas prácticas para elevar la calidad de la decisión de “go/no-go”
El artículo de Xray pone el acento en “asumir el control de la decisión de release” con evidencia de cobertura. En tu clase, puedes integrar estas buenas prácticas (en clave CTFL + gestión):
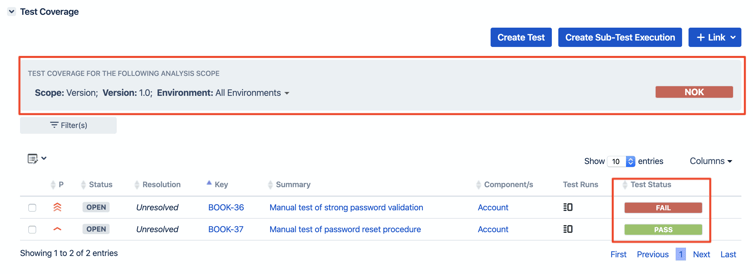
- Métricas por riesgo: no todas las unidades de código pesan igual. Elevar el umbral mínimo de “branch coverage” en componentes de alto impacto/riesgo produce una medida más informativa que un promedio global. (Recuerda al alumnado que “más cobertura” no es lo mismo que “mejor testing” si no está ponderada por riesgo).
- Puertas de calidad en CI/CD: usar la métrica de “code coverage” como “quality gate” (umbral) para bloquear un build que cae por debajo del mínimo. Esta es una aplicación natural de lo que el artículo llama “assess readiness to deploy”.
- Trazabilidad bidireccional: exigir que cada ítem crítico tenga pruebas automatizadas y que dichas pruebas impacten positivamente los indicadores de cobertura (evitar pruebas que no ejercitan el código relevante). Materiales de terceros sobre Xray explican esta convergencia de cobertura y trazabilidad.
- Visibilidad y conversaciones: la cobertura agrega transparencia al “reality check” pre-release. Los tableros de cobertura (código + requisitos) fomentan conversaciones con negocio sobre riesgo residual y alcance probado antes de liberar.
5) Limitaciones y matices (didáctica crítica)
Para que el alumnado no absolutice la métrica:
- Cobertura no prueba corrección funcional: ejecutar una línea no prueba su comportamiento correcto; se requieren aserciones sólidas y oráculos de prueba bien diseñados. (Este principio es consistente con CTFL y con la literatura técnica más amplia).
- “Branch coverage” alto no agota los caminos: caminos condicionados por múltiples decisiones pueden permanecer parcialmente inexplorados aun con alta cobertura de ramas; explica por qué el 100% de ramas no equivale a 100% de “path coverage”.
- Falsos positivos de confort: perseguir un umbral único (p. ej., “80% para todo”) puede ocultar brechas críticas en módulos de alto riesgo. (Algunas guías no oficiales popularizan “80%” como “ideal”, pero debes advertir que CTFL no impone un porcentaje; el umbral debe ser contextual).
- Datos y oráculos importan: un set de pruebas puede lograr cobertura alta con datos pobres o aserciones triviales; enfatiza diseño de pruebas (Cap. 4) y criterios de aceptación claros.
6) Cómo “atar” el discurso del artículo a tus resultados de aprendizaje CTFL
Tu pregunta original evaluaba la habilidad K2 de distinguir categorías de herramientas: cuando el objetivo es identificar código no ejecutado, la respuesta correcta es “code coverage”. El artículo de Xray te permite extender el contexto: cómo esa métrica se integra en un pipeline y en tableros para decidir despliegues. En términos prácticos para una clase:
- Definición (CTFL): mostrar fórmulas simples de “statement coverage” y “branch coverage”, y la relación de subsunción de ramas→sentencias. (Recalcar el alcance: cobertura ≠ corrección).
- Aplicación (gestión): presentar un tablero que combine cobertura estructural y estado de ítems cubribles; definir umbrales por riesgo y reglas “go/no-go”. (Este es el corazón del enfoque “readiness to deploy” del artículo).
- Discusión crítica: pedir a la clase que identifique dos escenarios donde “80% global” puede ser engañoso y proponga métricas ponderadas por riesgo, rutas críticas y decisiones con trazabilidad.
7) Ejemplo guiado para el aula (neutral a herramientas, inspirado en el artículo)
- Contexto: módulo de pagos con lógica de fraude (alto riesgo).
- Criterios previos: “branch coverage ≥ 90%” en el módulo de scoring y 100% de historias críticas con pruebas PASSED (unitarias + integración).
- Ejecución: CI instrumenta y produce el informe de cobertura; el gestor de pruebas refleja que todas las historias críticas tienen pruebas verdes.
- Análisis: el informe revela una rama no ejecutada en la lógica de “chargeback”, vinculada a una regla de negocio con test faltante.
- Decisión: no se despliega; se agrega un caso dirigido a esa rama, se re-ejecuta CI, y solo cuando la rama queda cubierta y la historia crítica en PASSED, se pasa a “go”.
Este mini-caso replica la idea de “assessment de readiness” por cobertura, pero en términos que el Syllabus legitima (métrica estructural + soporte de herramientas de gestión).

{kind=link}