
1. Introducción: El problema del «exceso de proactividad» de la IA
En la consultoría estratégica de IA, el mayor obstáculo para la escalabilidad no es la falta de potencia de los modelos, sino la inconsistencia operativa. Es una frustración que todos compartimos: solicitas un análisis técnico y recibes una respuesta de mil palabras cargada de verborragia, o peor aún, el modelo decide «ser útil» rellenando vacíos de información con datos inventados. Este «exceso de proactividad» no es un signo de inteligencia, sino un fallo de control que encarece los procesos de revisión y destruye la confianza en los entregables.
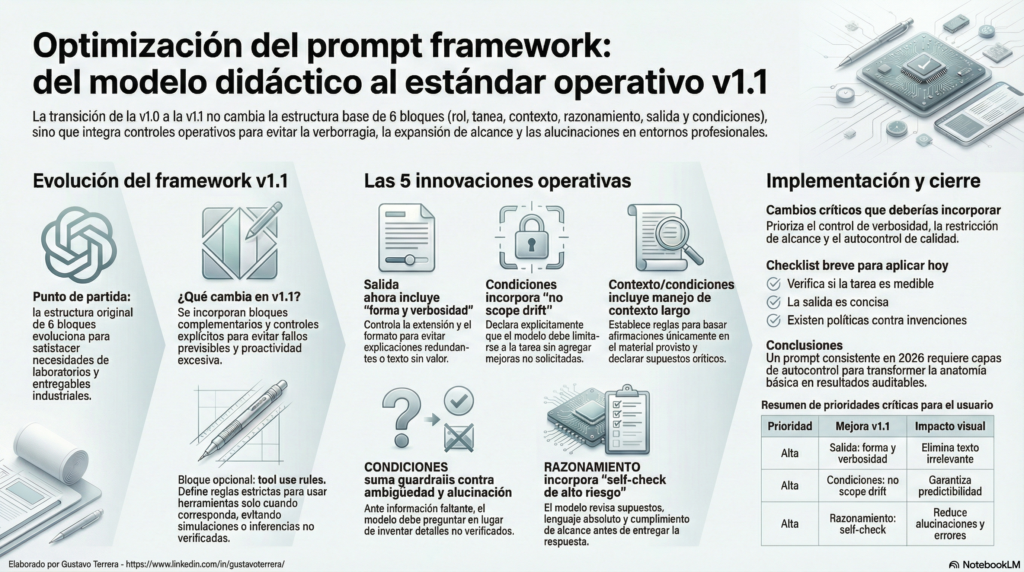
Para 2026, la «anatomía» didáctica de 6 bloques que dominó 2025 ha quedado atrás. Hemos evolucionado hacia el Estándar v1.1, un marco de trabajo industrial diseñado para transformar la interacción con la IA de un experimento creativo a un proceso repetible, auditable y libre de alucinaciones. En este artículo, desglosaremos cómo esta actualización técnica mitiga los riesgos operativos y garantiza la precisión en entornos de alta exigencia.
2. El Fin de la Verborragia: Controlar la Forma y Verbosidad
En el estándar v1.1, el bloque de SALIDA ha dejado de ser una simple descripción del formato. Ahora es una directriz de eficiencia de costos y tiempos de revisión. No basta con pedir «un reporte»; debemos definir la «forma y verbosidad» exacta. Este control es vital para mitigar las regresiones detectadas en modelos avanzados como GPT-5.2, donde el exceso de «agentic eagerness» (ansia de proactividad) tiende a diluir el valor técnico en párrafos de relleno.
Al establecer restricciones específicas de estructura y longitud, evitamos que el modelo mezcle análisis internos o justificaciones innecesarias con el entregable final. Esto reduce drásticamente los ciclos de revisión manual y asegura que la información relevante sea inmediatamente accionable.
«El control estricto de la verbosidad es un Standard Operating Procedure (SOP) indispensable: asegura resultados consistentes y fáciles de evaluar, impidiendo que el modelo consuma tokens y tiempo humano en explicaciones redundantes.»
3. «No Scope Drift»: Cuando Menos es Realmente Más
Uno de los mayores riesgos en la automatización industrial es la expansión del alcance no solicitada. Dentro del bloque de CONDICIONES, el estándar v1.1 impone la regla de «No scope drift». La IA debe limitarse estrictamente a la tarea encomendada, prohibiendo mejoras arbitrarias que, aunque parezcan útiles, suelen romper formatos de reporte, alterar protocolos de testing o desviar el foco estratégico.
Esta restricción aporta dos beneficios críticos para cualquier arquitectura de prompts profesional:
• Predictibilidad: El resultado se mantiene dentro de los márgenes definidos, facilitando su integración en flujos de trabajo automatizados.
• Integridad Estructural: Se eliminan los elementos «extra» que suelen corromper la estructura de datos esperada en reportes técnicos.
4. Contra la Alucinación: La Política de «Preguntar vs. Inventar»
Para un consultor senior, una IA que «adivina» es un riesgo inaceptable. La v1.1 introduce una política estricta de manejo de ambigüedad: ante la falta de datos críticos, el modelo tiene prohibido inventar. El protocolo exige que el modelo realice entre 1 y 3 preguntas aclaratorias o, en su defecto, plantee una propuesta basada en un SUPUESTO explícito.
Esta regla es fundamental al manejar contextos largos o documentación técnica compleja. Al forzar al modelo a basar cada afirmación exclusivamente en el material provisto, garantizamos la TRAZABILIDAD de la información. La capacidad de una IA para detenerse y preguntar no es una debilidad; es la máxima prueba de control y madurez operativa.
5. El «Self-check» de Alto Riesgo: El Filtro de Calidad Interno
El bloque de RAZONAMIENTO ya no es solo una guía lógica; en la versión v1.1 actúa como una capa interna de Quality Assurance (QA). Antes de emitir cualquier respuesta, el modelo debe ejecutar un «Self-check» obligatorio para auditar su propio borrador.
Los criterios de esta auditoría interna incluyen la detección de afirmaciones sin sustento, el uso de lenguaje absoluto injustificado y la verificación de expansión de alcance. Este paso transforma el output en un producto «auditable», permitiendo que los equipos de QA de prompts validen no solo el resultado final, sino el cumplimiento de las restricciones de seguridad y precisión impuestas en la instrucción.
• Pro Tip: Si utiliza herramientas externas (browsing, code interpreter), aplique las Tool Use Rules: prohíba al modelo «simular» resultados y exija que las conclusiones estén ancladas exclusivamente a lo obtenido por la herramienta.
6. Los Tres Pilares para Implementar Hoy
Para transicionar de un uso empírico a un estándar industrial, recomiendo adoptar de inmediato estas tres capas de control:
1. Eficiencia en la SALIDA (Forma y Verbosidad): Elimine el texto sin valor definiendo límites claros de longitud y estructura.
2. Integridad mediante CONDICIONES (No Scope Drift): Mitigue el riesgo de desviaciones prohibiendo explícitamente cualquier expansión del alcance original.
3. Mitigación de Riesgos (Ambigüedad + Self-check): Implemente la política de «preguntar antes de asumir» y la auditoría interna de razonamiento para asegurar la veracidad del entregable.
7. Conclusión: Hacia una IA Consistente
La evolución de la «anatomía» del prompt de 2025 a la consistencia operativa de 2026 marca la profesionalización definitiva del sector. Un prompt diseñado bajo el Estándar v1.1 no busca simplemente que la IA nos «entienda»; busca que se comporte de manera predecible y profesional bajo cualquier circunstancia.
Integrar estas capas explícitas de control —forma, límites de alcance y autocontrol de calidad— es lo que diferencia un experimento de una práctica industrial robusta, apta para la validación de entregables críticos y la generación de pruebas de alto nivel.
¿Cuál de estos tres problemas te ocurre más seguido: verborragia, expansión de alcance, o detalles inventados?


{kind=link}