
Hace unos días detecté algo que no había visto hasta ese momento
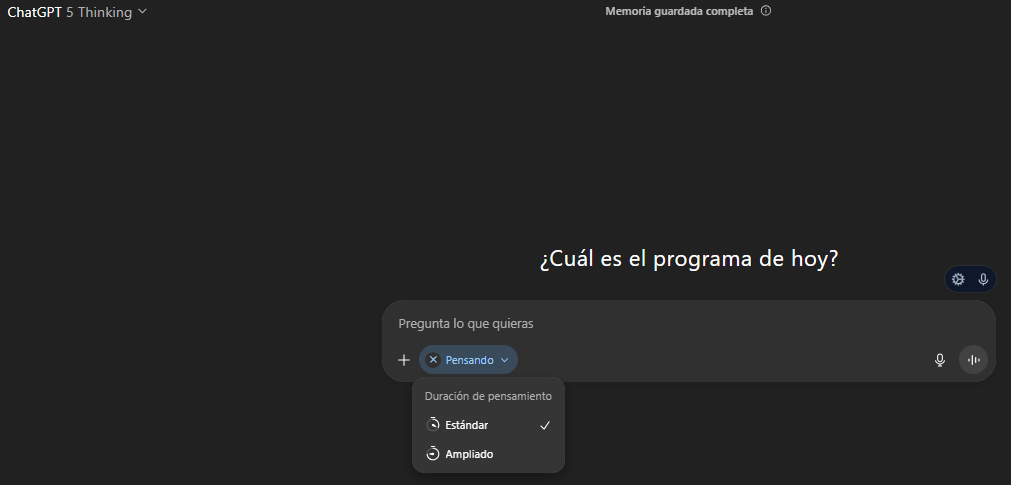
Esa opción “Pensando” controla cuánto tiempo deja razonar a GPT-5 Thinking antes de responder. Cuanto más “tiempo de pensamiento”, más pasos internos usa para planificar y chequear la respuesta—pero también tarda un poco más.
Es aquí donde debemos balancear nuestra interacción con el LLM, y ésto tiene que ver con nuestro rendimiento.
¿Cuál es la diferencia entre el modo Estándar y Ampliado?
| Modo | ¿Qué prioriza? | Cuándo conviene |
|---|---|---|
| Estándar | Equilibrio entre velocidad y calidad; es el nuevo valor por defecto. | Preguntas directas, resúmenes, listas de verificación rápidas, convertir notas a acciones. OpenAI Help Center+1 |
| Ampliado | Deja más tiempo de razonamiento para profundizar y encadenar pasos; era el valor por defecto anterior en Plus. | Tareas con varios condicionantes o pasos: estimación/planificación, análisis comparativo, diseño de estrategia de pruebas, priorización por riesgo. |
Dónde se cambia
Con GPT-5 (Thinking) activo en el chat, podemos ver un toggle de “tiempo de pensamiento” en el cuadro del mensaje (el chip azul “Pensando”), y al abrirlo podemos elegir entre el modo Estándar o Ampliado según la necesidad que tengamos.
Aquí es otro de los puntos que debemos considerar para pensar y preparar nuestra estrategia y aprovechar el tiempo y nuestro esfuerzo de manera eficiente y eficaz.
Nota: En caso de que tengas el plan Pro aparecen además el modo“Light” (más veloz) y “Heavy” (aún más profundo), pero si ves solo Estándar/Ampliado, estás en la configuración habitual de Plus/Business.
¿Qué modo elegir si tu rol es PM o Test Lead?
- Estándar:
- daily decisions,
- checklists DoD/DoR,
- reformular prompts,
- resúmenes para stakeholders.
- Ampliado:
- análisis causa-raíz,
- WSJF/VME,
- diseño de métricas/OKRs,
- planes de prueba híbridos
- y trade-offs con restricciones.
Guía práctica: “Tiempo de pensamiento” vs actividades de Testing Ágil
1) Mapeo por práctica (con base en Holistic Testing + Agile Testing Condensed + ISTQB TM)
| Práctica / Situación | Recomendado | Por qué (criterio pedagógico y técnico) |
|---|---|---|
| Cuadrantes Ágiles (Q1–Q4) – seleccionar tipos de pruebas y orden | Ampliado si definís estrategia; Estándar para recordar/explicar el modelo | En AT Condensed el capítulo “Agile Testing Quadrants” se usa como thinking tool para decidir qué pruebas y en qué orden; la variante Ampliado favorece el encadenado de razonamiento (trade-offs entre Q2/Q3, cobertura y riesgo). |
| Exploración continua + charters (touring, personas, workflows) | Ampliado al diseñar charters; Estándar para resumir hallazgos | En AT Condensed (“Explore Continuously”) y Holistic Testing (descubrir→planificar→colaborar) se requiere hipótesis, oráculos ligeros y heurísticas; Ampliado ayuda a generar charters ricos y supuestos verificables. |
| DoD colaborativo y vivo (criterios de aceptación, calidad incorporada) | Estándar para redactar/ajustar DoD; Ampliado si hay NFR/arquitectura | DoD típico es checklist operacional; cuando hay NFRs/arquitectura o “Definition of Done” enlazado a métricas de flujo y defectos escapados, Ampliado ayuda a alinear calidad–riesgo–valor. |
| Planeación multinivel (release/feature/story) + regresión | Ampliado al construir estrategia/capacidad; Estándar para artefactos | AT Condensed (“Test Planning in Agile Contexts: planning across levels”) + ISTQB TM v3 (Planificación, Estrategia y RBT): Ampliado soporta WSJF/VME, dependencias y ventanas; Estándar para producir planes/cronogramas ya decididos. |
| Example Mapping / EBT (guiding dev with examples) | Estándar para sesiones “3C” rápidas; Ampliado si hay reglas complejas | Cuando emergen reglas de negocio con excepciones y escenarios límite, Ampliado genera mejores particiones (ECP/BVA) y criterios de aceptación trazables. |
| Documentación viva y trazabilidad (living docs, ATDD/BDD) | Estándar para actualizar living docs; Ampliado para diseñar la malla | Si estás diseñando la malla de trazabilidad (Historia→Escenario→Prueba→Métrica), usa Ampliado; si sólo sincronizás cambios, Estándar. |
| Riesgo y estrategia (RBT, métricas de éxito, elección de enfoque) | Ampliado | ISTQB TM explicita Prueba basada en riesgo y Estrategia de proyecto; Ampliado mejora la priorización por valor-riesgo y justifica elecciones (mitigar/aceptar/transferir/escalar). |
| Monitoreo/Control de prueba y Reporting | Estándar | Para reportes periódicos (burnup/burndown, defectos, flow efficiency), Estándar es suficiente; si cambiás el modelo de métricas, pasa a Ampliado. |
En Holistic Testing (model “descubrir → planificar → colaborar → ejecutar → aprender”), el modo Ampliado encaja mejor en los pasos de descubrir/planificar/aprender; Estándar en colaborar/ejecutar cuando ya tenés el marco acordado.
¿Qué es eso de los reasoning tokens?
Los modos de razonamiento consumen “reasoning tokens” internos adicionales.
Los reasoning tokens son una forma de medir el costo computacional que un modelo de lenguaje, como los de ChatGPT, utiliza para realizar tareas de razonamiento. En lugar de limitarse a dar la siguiente palabra, el modelo consume estos tokens cuando necesita seguir un proceso lógico para llegar a una respuesta.
Funcionamiento y propósito
Cuando le pides a un modelo que resuelva un problema complejo, como que genere un plan detallado de testing de seguridad, el modelo no lo hace de un solo intento. Internamente, sigue un proceso de pensamiento, llamado cadena de pensamiento (chain-of-thought). Este proceso desglosa el problema en pasos más pequeños. Cada uno de estos pasos consume reasoning tokens.
El propósito de este concepto tiene dos fines:
- Mejora de la precisión: El modelo tiene más «oportunidad» de corregirse y refinar su respuesta en cada paso intermedio, lo que conduce a resultados más precisos y menos propensos a errores.
- Optimización de costos: Al tener un modelo que puede razonar, se evita gastar una cantidad enorme de tokens en la respuesta final de una sola vez, ya que los pasos intermedios guían al modelo hacia una respuesta más eficiente y correcta.
¿Cómo lograr mayor eficiencia en el consumo de reasoning tokens?
Para lograr un consumo más eficiente de reasoning tokens en un modelo como ChatGPT, se pueden aplicar varias estrategias centradas en la optimización del input y la estructuración de la tarea. La clave es reducir la cantidad de «pensamiento» innecesario que el modelo debe realizar.
1. Ser específico y conciso en tu prompt
Un prompt claro y directo es la forma más efectiva de reducir el consumo. Evita los detalles de fondo largos que no son esenciales para la pregunta principal.
- Mal ejemplo: «He estado trabajando en este proyecto y ahora necesito que me ayudes. El proyecto trata sobre marketing y he estado investigando durante meses. ¿Podrías, por favor, resumir las notas de la reunión que te adjunto?»
- Buen ejemplo: «Resume las siguientes notas de la reunión en 5 puntos de acción clave.»
2. Establecer límites de respuesta
Al indicarle al modelo que la respuesta debe ser de cierta longitud, lo guías para que no gaste tokens en generar texto innecesario.
- «Responde en menos de 200 palabras.»
- «Genera una lista de 3 puntos.»
3. Dividir las tareas complejas en pasos más pequeños
En lugar de pedir al modelo que haga una tarea grande de una vez, divídela en varias solicitudes. Esto es especialmente útil en el desarrollo de aplicaciones que usan la API de los modelos, donde cada solicitud se mantiene dentro de los límites de tokens establecidos.
4. Resumir el contexto
Si estás en una conversación larga o si el texto de entrada es muy extenso, resume los puntos clave antes de hacer la siguiente pregunta. Por ejemplo, en lugar de pegar 10 páginas de texto para tu análisis, puedes pedirle al modelo que las resuma primero y luego trabajar con ese resumen.
El siguiente video nos ayuda a entender un poco más este tema


{kind=link}