
Desde la página oficial de OpenAI fué publicada la novedad del nuevo modelo «o3-mini» y luego de leerlo me pareció importante profundizar en su contenido para poder comprender su alcance y luego, analizar los diferentes tipos de pruebas y métricas aplicadas en sus correspondientes ensayos.
Acerca del subtítulo «Pushing the frontier of cost-effective reasoning»
Fué lo primero que intenté conocer para entenderlo.
Significa avanzar en los límites del modelo de la inteligencia artificial en cuanto a su capacidad de razonamiento, haciéndola al mismo tiempo más accesible y económica.
Por un lado hay que entender que se refiere a llevar la tecnología de IA a nuevos niveles en cuanto a sus capacidades de razonamiento, explorando territorios desconocidos y descubriendo nuevas posibilidades.
Por otro lado, también hay que considerar que la tecnología ofrece una buena relación calidad-precio, es decir que en el contexto de la IA, implica que se está buscando un equilibrio entre el rendimiento (la capacidad de razonamiento) y el costo (tanto económico como computacional). Por lo tanto, es de entenderse que se trata de crear una IA que sea lo suficientemente inteligente a un precio razonable.
Por último, y no menor, el modelo trata la capacidad de la IA para pensar lógicamente, resolver problemas, tomar decisiones y extraer conclusiones a partir de la información disponible, facultando a la IA para que vaya más allá de que memorice y manipule datos, y que pueda llegar a comprender y utilizar la información de manera inteligente. ¿Será que ese es el “gran reto”?
¿Será que el modelo “o3-mini” es más accesible y asequible?
Aquí, como primera medida intenté resolver mi primera duda: ¿Cuál es el concepto de “accesible” y “asequible” en el contexto de la IA?
Accesible
Se refiere a la facilidad con la que algo puede ser usado, comprendido o alcanzado. No se limita al precio, sino a la posibilidad de acceder y usar sin importar las capacidades, ubicación o nivel de conocimiento.
Ejemplos:
- Una página web es accesible si personas con discapacidad visual pueden navegar usando un lector de pantalla.
- Un software es accesible si su interfaz es intuitiva y fácil de usar para personas de diferentes edades y niveles de experiencia.
- Un servicio es accesible si está disponible en diferentes lugares y horarios, adaptándose a las necesidades de los usuarios.
Estos ejemplos son entendibles para nosotros, los “agile testers”, ¿verdad?
Asequibilidad
Se refiere principalmente al costo económico de algo. Algo es asequible si su precio permite que un amplio sector de la población pueda adquirirlo.
Ejemplos:
- Un teléfono móvil es asequible si su precio es bajo o existen planes de financiamiento accesibles.
- Una vivienda es asequible si su costo no supera un porcentaje razonable de los ingresos de una familia.
- Un servicio es asequible si su precio es competitivo y se ajusta al presupuesto de los usuarios.
Entonces, y para ir cerrando la idea inicial, en el contexto de la IA (Inteligencia Artificial):
- Accesibilidad: Concepto que refiere a que la IA sea fácil de usar, comprender y aplicar, independientemente de las habilidades técnicas que tenga el usuario. Es decir, poder contar con interfaces intuitivas, documentación clara y herramientas que permitan a personas sin conocimientos especializados aprovechar la IA. De alguna manera, es lo que todos deseamos, que todos puedan usar las nuevas tecnologías sin mayores esfuerzos.
- Asequibilidad: Concepto que refiere a que el costo de acceder a la tecnología de IA sea lo suficientemente bajo como para que personas y organizaciones con diferentes presupuestos puedan utilizarla. Esto implica precios competitivos, modelos de pago flexibles y opciones gratuitas o de bajo costo para ciertos usos.También es lo que todos intentamos tener justamente para que todo el conocimiento sea accesible. Ojalá que suceda, es un deseo personal.
En resumen
- Accesibilidad: Facilidad de uso y comprensión.
- Asequibilidad: Costo económico accesible.
OpenAI o3-mini: Razonamiento potente y rentable para Agile Testers y Project Managers
En el mundo del desarrollo de software y la gestión de proyectos, la eficiencia y la precisión son clave. Por eso, el nuevo modelo “o3-mini” de Inteligencia Artificial (IA) de OpenAI propone que puede estar revolucionando la forma en que abordamos los desafíos técnicos y de gestión.
¿Qué es OpenAI “o3-mini” y por qué es importante?
“o3-mini” es el modelo más reciente y rentable de la serie de razonamiento de OpenAI. Pero, ¿qué significa esto? En pocas palabras, o3-mini es capaz de «pensar» y resolver problemas complejos de manera más rápida y precisa, especialmente en áreas como las de STEM (Ciencia, Tecnología, Ingeniería y Matemáticas). Esta capacidad es fundamental para Agile Testers que buscan optimizar sus procesos de prueba y Project Managers que necesitan tomar decisiones informadas en entornos ágiles. Pronto estaré publicando contenido de frameworks de prompts para atender necesidades de estos roles.
Costo-efectividad y rapidez
Una de las principales ventajas del modelo “o3-mini” es su costo-efectividad. OpenAI ha logrado crear un modelo potente que no comprometa el presupuesto de tu proyecto. Además, su rapidez es impresionante, lo que significa que puedes obtener resultados en tiempo real y mantener el ritmo de trabajo en proyectos ágiles. Para medir verdaderamente dicho resultado, deberías realizar un ensayo comparativo con los modelos anteriores utilizando el mismo prompt.
Niveles de razonamiento que nos permiten la adaptación
El modelo “o3-mini” ofrece tres niveles de razonamiento: bajo, medio y alto. Esta flexibilidad te permite ajustar la «intensidad» del pensamiento de la IA según la complejidad del problema. Recordemos aquí que en el ChatGPT podemos acceder a la funcionalidad de “intensidad” para cambiar el grado de respuesta como resultado del prompt que hayamos suministrado. Para tareas sencillas, un nivel bajo será suficiente, mientras que para desafíos más complejos, un nivel alto garantizará la precisión necesaria. Para medir este resultado y que tiene tres variables, también hay que realizar cierto tipo de ensayos con precondiciones específicas habiendo establecido la variable correspondiente a cada tipo de “intensidad”.
Casos de uso en el contexto de marcos ágiles
- Agile Testing: “o3-mini” nos puede ayudar en lo siguiente:
- Automatizar la generación de casos de prueba complejos, reduciendo el tiempo y el esfuerzo manual.
- Analizar grandes conjuntos de datos de prueba para identificar patrones y anomalías, mejorando la calidad del software.
- Optimizar la priorización de pruebas, asegurando que los recursos se centren en las áreas más críticas.
- Agile Project Management (PMI-ACP): o3-mini nos puede ayudar en lo siguiente:
- Estimar el esfuerzo y los recursos necesarios para las tareas del proyecto, mejorando la planificación.
- Identificar riesgos y dependencias entre tareas, permitiendo una gestión proactiva.
- Tomar decisiones informadas basadas en el análisis de datos y la simulación de escenarios, maximizando el éxito del proyecto.
OpenAI o3-mini: Potencia y precisión en razonamiento STEM
OpenAI o3-mini, el nuevo modelo de IA de OpenAI, se destaca por su velocidad, potencia y optimización para el razonamiento en áreas STEM (Ciencia, Tecnología, Ingeniería y Matemáticas). Siguiendo los pasos de modelos anteriores: o1, el nuevo modelo “o3-mini” ha sido específicamente diseñado para sobresalir en este campo (STEM), ofreciendo mejoras significativas en comparación con la versión anterior “o1-mini”.
Una de las principales ventajas del modelo “o3-mini” es su velocidad. El modelo es capaz de generar respuestas rápidamente, lo que lo convierte en una herramienta ideal para entornos donde el tiempo es crucial. ¿Cómo probarías dicha característica? ¿Que precondiciones deberías tener en cuenta? ¿Cuáles serían tus principales variables? ¿Que resultados deberías estar esperando? ¿En que instancia del proceso de pruebas en un entorno ágil aplicarías el o los ensayos?
En cuanto a su rendimiento en razonamiento STEM, el modelo “o3-mini” con un esfuerzo de razonamiento medio iguala el rendimiento del modelo “o1” en matemáticas, programación y ciencias. Esto significa que ofrece la misma capacidad de resolución de problemas complejos, pero con la ventaja de una mayor velocidad y con menor esfuerzo.
Pero las mejoras no terminan ahí. Evaluaciones realizadas por expertos han demostrado que el modelo “o3-mini” produce respuestas más precisas y claras, con habilidades de razonamiento superiores a las del modelo “o1-mini”. En pruebas comparativas, los testers que han evaluado los modelos han preferido las respuestas del modelo “o3-mini” en un 56% y observaron una reducción del 39% en errores importantes en preguntas difíciles del mundo real. Esta mejora en la precisión es muy interesante de tener presente para aplicaciones donde la exactitud es un factor prioritario.
Además, con un esfuerzo de razonamiento medio, el modelo “o3-mini” iguala el rendimiento del modelo “o1” en algunas de las pruebas de razonamiento e inteligencia más desafiantes, incluyendo AIME y GPQA. Esto demuestra la capacidad del modelo para abordar problemas de alta complejidad y ofrecer soluciones confiables.
Aquí hago un stop para buscar y compartir el concepto de AIME y GPQA.
AIME
- AIME son las siglas de American Invitational Mathematics Examination (Examen Estadounidense de Matemáticas por Invitación).
- Es un examen de matemáticas de alto nivel que se realiza en Estados Unidos y que sirve como paso previo para la selección del equipo olímpico de matemáticas de ese país.
- Características:
- Está dirigido a estudiantes de secundaria con un gran talento para las matemáticas.
- Consta de 15 problemas de dificultad creciente que deben resolverse en un tiempo limitado.
- Los problemas suelen requerir un alto nivel de ingenio y creatividad para su resolución.
- Importancia: Es una prueba prestigiosa que evalúa la capacidad de los estudiantes para resolver problemas matemáticos complejos y que sirve como filtro para identificar a los futuros talentos en esta disciplina.
GPQA
- GPQA son las siglas de Graduate-Level Physics Questions and Answers (Preguntas y Respuestas de Física a Nivel de Posgrado).
- Es un conjunto de datos que contiene preguntas de física a nivel de doctorado, junto con sus respuestas correspondientes.
- Características:
- Las preguntas abarcan diversas áreas de la física, como mecánica, electromagnetismo, termodinámica, etc.
- Las preguntas son de alta complejidad y requieren un profundo conocimiento de la materia para poder responderlas correctamente.
- Importancia: Se utiliza para evaluar la capacidad de los modelos de IA para comprender y responder preguntas científicas de alto nivel. Es un indicador de la capacidad de la IA para razonar y resolver problemas complejos en el campo de la física.
De aquí en adelante estaré analizando e interpretando una serie de imágenes que demuestran los ensayos realizados sobre el modelo “o3-mini” y sus resultados.
Examen de matemáticas AIME 2024
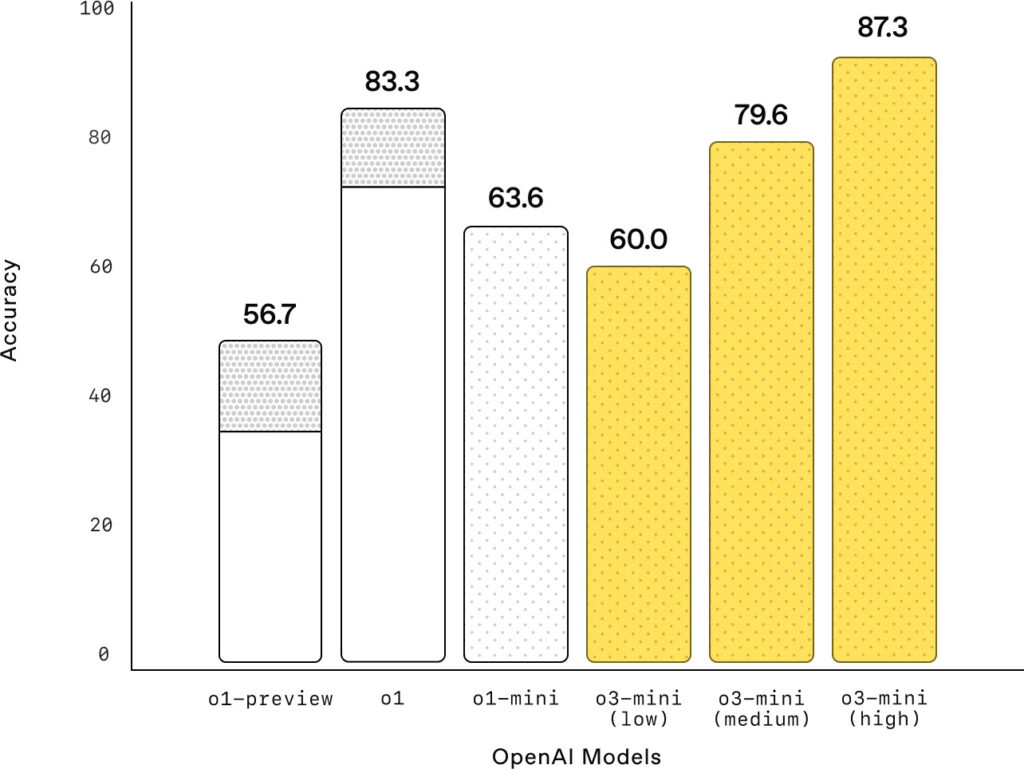
La gráfica muestra el rendimiento de los modelos de OpenAI en el examen de matemáticas AIME 2024, una prueba de alta dificultad. Los resultados son reveladores y demuestran el avance significativo que representa el modelo “o3-mini” en el campo del razonamiento matemático.
En primer lugar, es importante observar que el eje vertical de la gráfica representa la precisión (Accuracy) de los modelos, es decir, el porcentaje de respuestas correctas que son capaces de generar. El eje horizontal muestra los diferentes modelos de OpenAI, incluyendo las distintas versiones de “o3-mini” con diferentes niveles de esfuerzo de razonamiento.
Los resultados muestran que o3-mini, con un esfuerzo de razonamiento bajo (low), alcanza un rendimiento comparable al de o1-mini. Esto ya es un logro, considerando que el modelo “o3-mini” es más rápido y eficiente.
Sin embargo, la verdadera fortaleza del modelo “o3-mini” se revela al aumentar el esfuerzo de razonamiento. Con un esfuerzo medio (medium), o3-mini iguala el rendimiento de o1, el modelo de razonamiento general más potente de OpenAI hasta el momento. Esto significa que o3-mini es capaz de alcanzar el mismo nivel de precisión que o1 en matemáticas, pero con un costo computacional menor.
Pero el avance más destacado se produce con un esfuerzo de razonamiento alto (high). En este escenario, o3-mini supera tanto a o1-mini como a o1, alcanzando una precisión significativamente mayor. Este resultado subraya la capacidad del modelo “o3-mini” para abordar problemas matemáticos complejos y ofrecer soluciones precisas cuando se le da la oportunidad de «pensar más».
La gráfica también muestra las regiones sombreadas en gris, que representan el rendimiento de la votación por mayoría (consensus) con 64 muestras. Esta técnica consiste en generar múltiples respuestas para un mismo problema y luego seleccionar la respuesta que aparece con mayor frecuencia. Como se puede observar, o3-mini con un esfuerzo de razonamiento alto se acerca al rendimiento de la votación por mayoría, lo que demuestra su capacidad para generar respuestas de alta calidad de manera consistente.
Brillando en preguntas científicas de nivel doctoral
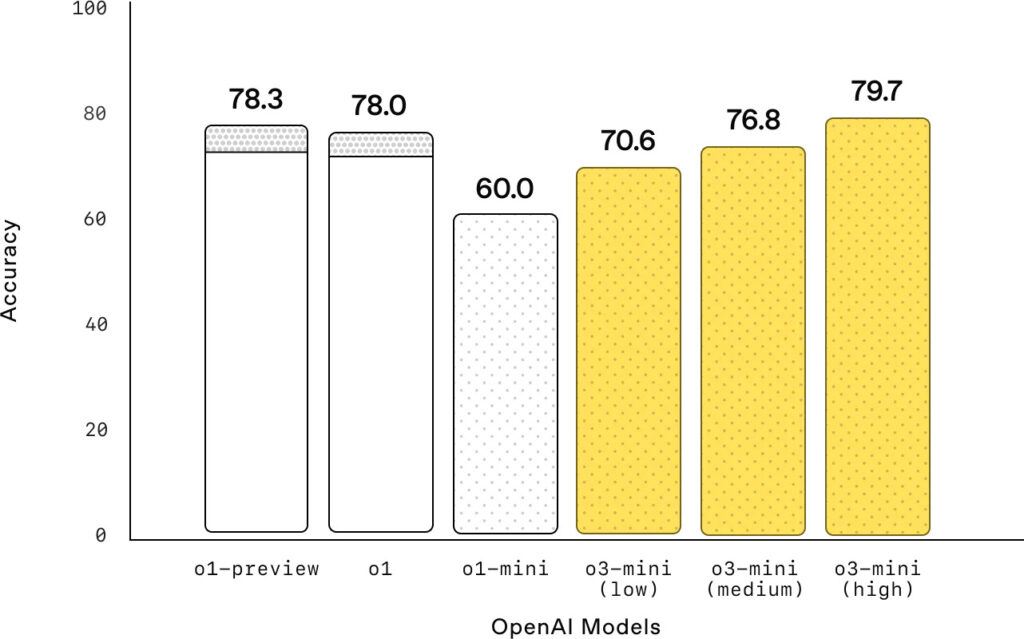
La gráfica muestra el rendimiento de los modelos de OpenAI en GPQA Diamond, un conjunto de datos que contiene preguntas de ciencia a nivel de doctorado en biología, química y física. Los resultados resaltan la capacidad del modelo “o3-mini” para abordar preguntas científicas complejas, especialmente al aumentar el esfuerzo de razonamiento.
El eje vertical de la gráfica representa la precisión (Accuracy) de los modelos, es decir, el porcentaje de respuestas correctas que generan. El eje horizontal muestra los diferentes modelos de OpenAI, incluyendo las distintas versiones de o3-mini con diferentes niveles de esfuerzo de razonamiento.
Observamos que o3-mini, con un esfuerzo de razonamiento bajo (low), supera a o1-mini en preguntas científicas de nivel de doctorado. Este es un primer indicio del potencial de o3-mini para abordar temas científicos complejos incluso con un esfuerzo de razonamiento limitado.
A medida que aumentamos el esfuerzo de razonamiento, el rendimiento de o3-mini mejora notablemente. Con un esfuerzo alto (high), o3-mini alcanza un rendimiento comparable al de o1, el modelo de razonamiento general más potente de OpenAI. Este resultado subraya la capacidad de o3-mini para comprender y responder preguntas científicas de alta complejidad, demostrando un nivel de razonamiento avanzado en este campo.
Es importante destacar que la gráfica también muestra el rendimiento de o1-preview y o1, los cuales se mantienen relativamente estables con independencia del esfuerzo de razonamiento. En cambio, o3-mini experimenta una mejora significativa al pasar de un esfuerzo bajo a uno alto, lo que sugiere que este modelo es capaz de aprovechar mejor el incremento en el «tiempo de pensamiento» para abordar preguntas más complejas.
Resolviendo desafíos matemáticos de investigación con FrontierMath

La tabla muestra el rendimiento de diferentes modelos de OpenAI en FrontierMath, un conjunto de problemas matemáticos de nivel de investigación. Los resultados demuestran la capacidad superior del modelo “o3-mini” con un esfuerzo de razonamiento alto para abordar desafíos matemáticos complejos, incluso sin herramientas externas.
La tabla presenta tres métricas clave: Pass@1, Pass@4 y Pass@8. Estas métricas indican el porcentaje de problemas que se resuelven correctamente en el primer intento, en cuatro intentos y en ocho intentos, respectivamente. En otras palabras, miden la eficiencia del modelo para encontrar la solución correcta dentro de un número determinado de intentos.
Los resultados muestran que o3-mini con un esfuerzo de razonamiento alto (high) supera a sus predecesores, o1-mini y o1, en todas las métricas. Esto demuestra que o3-mini es más eficaz para resolver problemas matemáticos de investigación que los modelos anteriores.
Específicamente, o3-mini (high) logra una tasa de éxito del 9.2% en el primer intento (Pass@1), del 16.6% en cuatro intentos (Pass@4) y del 20% en ocho intentos (Pass@8). Estas cifras son significativamente más altas que las de o1-mini y o1, lo que subraya la mejora en el rendimiento que representa o3-mini.
Es importante tener en cuenta que estos resultados se obtuvieron sin el uso de herramientas externas ni calculadoras. El texto asociado menciona que, al utilizar una herramienta de Python, o3-mini con un esfuerzo de razonamiento alto resuelve más del 32% de los problemas en el primer intento, incluyendo más del 28% de los problemas desafiantes de nivel T3. Esto demuestra el potencial aún mayor de o3-mini cuando se combina con herramientas adecuadas.
Escalando posiciones en la programación competitiva
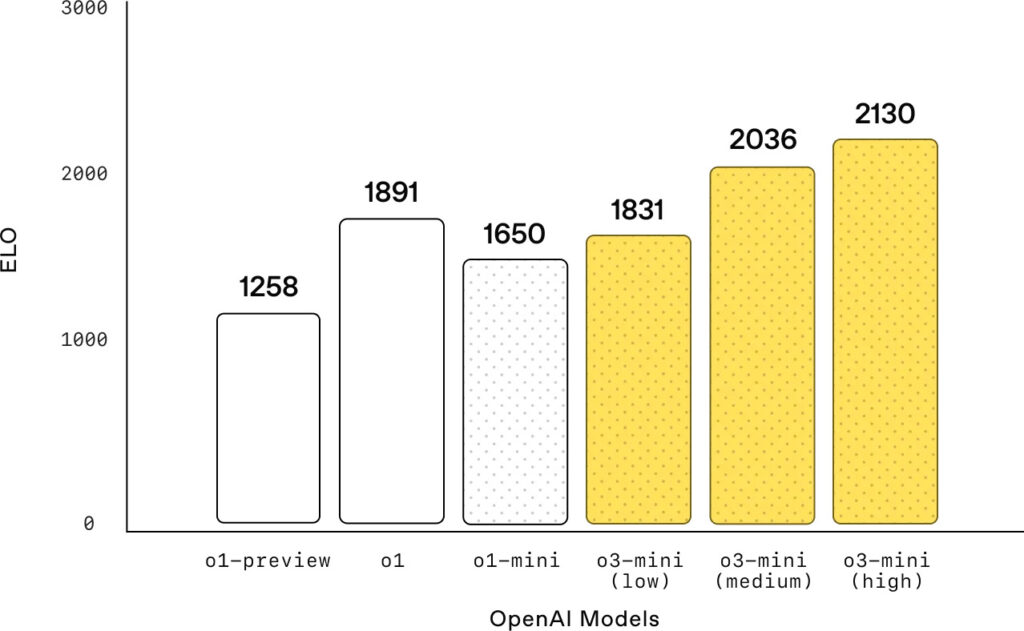
La gráfica muestra el rendimiento de los modelos de OpenAI en Codeforces, una plataforma popular para la programación competitiva. Los resultados demuestran que el modelo “o3-mini”, a medida que aumenta su esfuerzo de razonamiento, mejora significativamente su ELO, una medida de habilidad en este tipo de competiciones.
El eje vertical de la gráfica representa el ELO alcanzado por los diferentes modelos. Un ELO más alto indica un mejor rendimiento en la programación competitiva. El eje horizontal muestra los modelos de OpenAI, incluyendo las distintas versiones de o3-mini con diferentes niveles de esfuerzo de razonamiento.
Los resultados muestran una clara tendencia: a medida que se incrementa el esfuerzo de razonamiento, o3-mini obtiene un ELO progresivamente mayor. o3-mini con un esfuerzo bajo (low) ya supera a o1-mini, lo que indica una mejora inicial en la capacidad para resolver problemas de programación competitiva.
La mejora se vuelve más evidente con un esfuerzo medio (medium). En este punto, o3-mini iguala el rendimiento de o1, el modelo de razonamiento general más potente de OpenAI. Esto sugiere que o3-mini es capaz de alcanzar el mismo nivel de habilidad en programación competitiva que o1, pero con la ventaja de ser más rápido y eficiente.
Finalmente, con un esfuerzo de razonamiento alto (high), o3-mini alcanza el ELO más alto de todos los modelos mostrados. Este resultado subraya la capacidad de o3-mini para abordar problemas de programación complejos y encontrar soluciones óptimas cuando se le da la oportunidad de «pensar más».
Liderando en Ingeniería de Software con SWE-bench Verified

La gráfica muestra el rendimiento de los modelos de OpenAI en SWE-bench Verified, un conjunto de datos diseñado para evaluar la capacidad de los modelos de lenguaje en tareas de ingeniería de software. Los resultados destacan el liderazgo de o3-mini en este campo, superando a sus predecesores y demostrando un rendimiento superior en tareas de programación.
El eje vertical de la gráfica representa la precisión (Accuracy) de los modelos, es decir, el porcentaje de tareas de ingeniería de software que completan correctamente. El eje horizontal muestra los diferentes modelos de OpenAI, incluyendo las distintas versiones de o3-mini con diferentes niveles de esfuerzo de razonamiento.
Los resultados muestran que o3-mini es el modelo publicado con mejor rendimiento en SWE-bench Verified. Con un esfuerzo de razonamiento alto (high), o3-mini alcanza una precisión del 49.3%, superando a todos los demás modelos mostrados en la gráfica. Este resultado subraya la capacidad de o3-mini para abordar tareas complejas de ingeniería de software y generar código de alta calidad.
Es importante observar que o3-mini muestra una mejora constante en su rendimiento a medida que aumenta el esfuerzo de razonamiento. Con un esfuerzo bajo (low), alcanza una precisión del 40.8%, mientras que con un esfuerzo medio (medium), llega al 42.9%. Esta tendencia demuestra que o3-mini es capaz de aprovechar el incremento en el «tiempo de pensamiento» para mejorar su rendimiento en tareas de programación.
El texto asociado menciona resultados adicionales para o3-mini con un esfuerzo de razonamiento alto utilizando diferentes «scaffolds» (estructuras) en SWE-bench Verified. Específicamente, se menciona un rendimiento del 39% con el scaffold Agentless de código abierto y un 61% con un scaffold de herramientas internas. Estos resultados adicionales demuestran el potencial de o3-mini para adaptarse a diferentes entornos y herramientas de desarrollo.
Eficiencia y rendimiento superior en LiveBench Coding
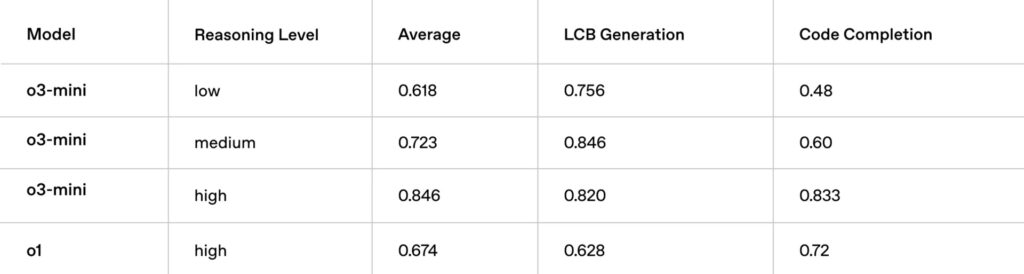
La tabla muestra el rendimiento de o3-mini en comparación con o1 en LiveBench Coding, un entorno para evaluar la capacidad de los modelos de lenguaje en tareas de codificación en tiempo real. Los resultados resaltan la eficiencia de o3-mini, superando a o1 incluso con un esfuerzo de razonamiento medio, y demostrando un rendimiento significativamente mayor con un esfuerzo alto.
La tabla presenta tres métricas clave: Average (Promedio), LCB Generation (Generación de LCB) y Code Completion (Finalización de Código). Estas métricas evalúan diferentes aspectos de la capacidad de codificación de los modelos, incluyendo la precisión general, la capacidad para generar código en un contexto específico (LCB) y la habilidad para completar fragmentos de código de manera efectiva.
Los resultados muestran que o3-mini supera a o1-high (o1 con esfuerzo alto) incluso con un esfuerzo de razonamiento medio (medium). Específicamente, o3-mini (medium) alcanza un promedio de 0.723, una generación de LCB de 0.846 y una finalización de código de 0.60, mientras que o1-high obtiene 0.674, 0.628 y 0.72, respectivamente. Esta diferencia subraya la eficiencia de o3-mini, ya que logra un mejor rendimiento con menos «esfuerzo de pensamiento».
Con un esfuerzo de razonamiento alto (high), o3-mini extiende aún más su ventaja, alcanzando un promedio de 0.846, una generación de LCB de 0.820 y una finalización de código de 0.833. Estos resultados demuestran el potencial de o3-mini para abordar tareas de codificación complejas y generar código de alta calidad cuando se le da la oportunidad de «pensar más».
El texto asociado destaca la eficiencia de o3-mini en tareas de codificación, enfatizando que supera a o1-high incluso con un esfuerzo de razonamiento medio. Además, se menciona que con un esfuerzo alto, o3-mini extiende aún más su ventaja, logrando un rendimiento significativamente mayor en todas las métricas clave.
Ampliando sus capacidades en conocimiento general
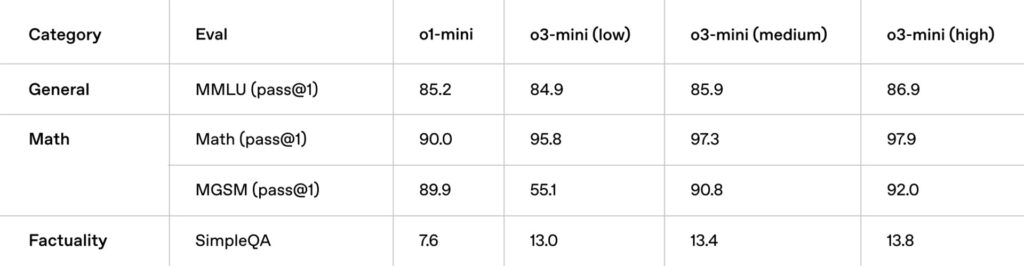
La tabla muestra el rendimiento de o3-mini en comparación con o1-mini en diversas evaluaciones de conocimiento general. Los resultados demuestran que o3-mini no solo sobresale en tareas STEM, sino que también supera a o1-mini en el ámbito del conocimiento general, abarcando áreas como comprensión del lenguaje, matemáticas y factibilidad.
La tabla presenta cuatro categorías de evaluación: General, Math (Matemáticas) y Factuality (Factibilidad). Cada categoría incluye una o dos métricas específicas. Es importante notar que todas las métricas son pass@1, lo que significa que miden el porcentaje de respuestas correctas en el primer intento.
En la categoría General, se utiliza la métrica MMLU (pass@1), que evalúa la comprensión del lenguaje en una amplia gama de temas. Los resultados muestran que o3-mini supera a o1-mini en todas las versiones, con una mejora que va desde un 0.7% (low vs. low) hasta un 1.7% (high vs. low).
En la categoría Math, se utilizan dos métricas: Math (pass@1) y MGSM (pass@1). La primera evalúa la capacidad para resolver problemas matemáticos, mientras que la segunda se enfoca en problemas de matemáticas más complejos. Nuevamente, o3-mini supera a o1-mini en todas las versiones en ambas métricas. En Math (pass@1), la mejora es notable, con o3-mini (high) alcanzando un 97.9% frente al 90.0% de o1-mini. En MGSM (pass@1), la mejora es aún más significativa, especialmente con un esfuerzo de razonamiento alto, donde o3-mini alcanza un 92.0% frente al 89.9% de o1-mini.
En la categoría Factuality, se utiliza la métrica SimpleQA, que evalúa la capacidad para responder preguntas factuales simples. Aquí también, o3-mini supera a o1-mini en todas las versiones, aunque la diferencia es menor en comparación con las otras categorías.
El texto asociado a la imagen destaca que o3-mini supera a o1-mini en evaluaciones de conocimiento en dominios de conocimiento general. Los resultados de la tabla confirman esta afirmación, mostrando mejoras consistentes en todas las categorías y métricas evaluadas.
Evaluación de preferencias humanas
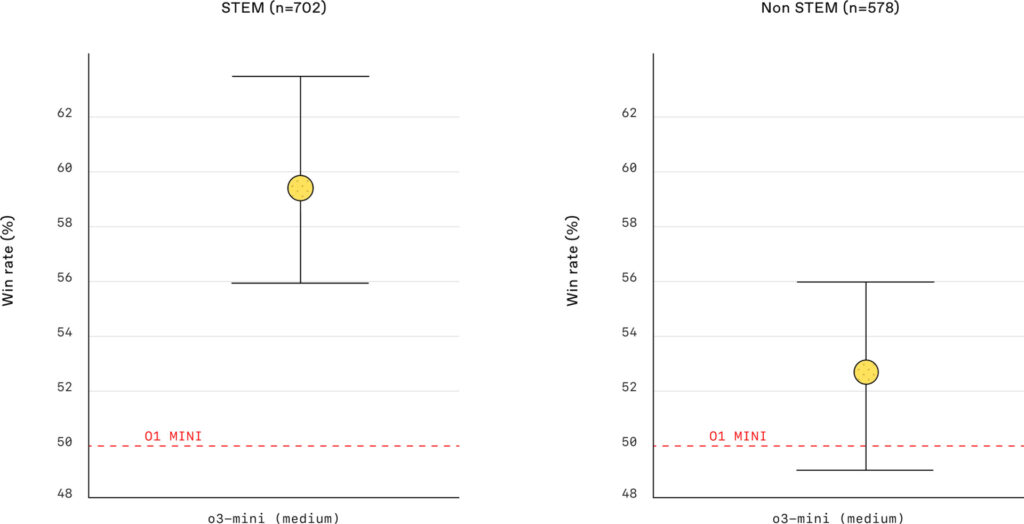
Las imágenes muestran los resultados de una evaluación de preferencias humanas, donde expertos externos compararon las respuestas de o3-mini (con esfuerzo de razonamiento medio) y o1-mini en preguntas del mundo real, divididas en dos categorías: STEM (Ciencia, Tecnología, Ingeniería y Matemáticas) y No STEM. Los resultados destacan la preferencia significativa por o3-mini, especialmente en el ámbito STEM, lo que subraya sus capacidades superiores en razonamiento y precisión.
En el gráfico de la izquierda, que representa la categoría STEM (n=702 preguntas), se observa que o3-mini (medium) supera a o1-mini. La línea roja discontinua representa el rendimiento de o1-mini, mientras que el punto amarillo representa el rendimiento de o3-mini (medium) con su intervalo de confianza. Visualmente, se aprecia que el punto amarillo está claramente por encima de la línea roja, lo que indica una mayor tasa de victorias (win rate) para o3-mini en preguntas STEM.
En el gráfico de la derecha, que representa la categoría No STEM (n=578 preguntas), también se observa una tendencia favorable hacia o3-mini (medium), aunque la diferencia no es tan marcada como en la categoría STEM. Nuevamente, el punto amarillo está por encima de la línea roja, lo que sugiere que o3-mini también ofrece mejores respuestas en preguntas no STEM, pero con una ventaja menor.
El texto asociado a las imágenes complementa esta información al destacar que las evaluaciones realizadas por expertos externos muestran que o3-mini produce respuestas más precisas y claras, con habilidades de razonamiento más sólidas que o1-mini, especialmente en el ámbito STEM. Se menciona específicamente que los evaluadores prefirieron las respuestas de o3-mini al 56% de las veces y observaron una reducción del 39% en errores importantes en preguntas difíciles del mundo real.
Esta preferencia por o3-mini se refleja en los gráficos, donde se observa un mayor rendimiento en ambas categorías, aunque más pronunciado en STEM. La reducción del 39% en errores importantes es un indicador clave de la mejora en la precisión y confiabilidad de las respuestas generadas por o3-mini.
Velocidad, eficiencia y rendimiento superior
A lo largo del análisis, OpenAI o3-mini se destaca por sus capacidades de razonamiento, especialmente en el ámbito STEM, superando a modelos anteriores como o1-mini y, en muchos casos, igualando o superando a o1. Ahora, se incorporan dos nuevos factores: la velocidad y la eficiencia.
El modelo «o3-mini» no solo es inteligente, sino también rápido y eficiente. A pesar de tener una inteligencia comparable a o1, o3-mini ofrece un rendimiento más veloz y una mayor eficiencia. Esto significa que puede realizar las mismas tareas que o1 (o incluso mejorarlas) en menos tiempo y con menos recursos.
Más allá de las evaluaciones STEM ya mencionadas, o3-mini también demuestra resultados superiores en evaluaciones adicionales de matemáticas y factibilidad con un esfuerzo de razonamiento medio. Esto refuerza la idea de que o3-mini es un modelo completo y versátil, capaz de destacar en diversas áreas del conocimiento.
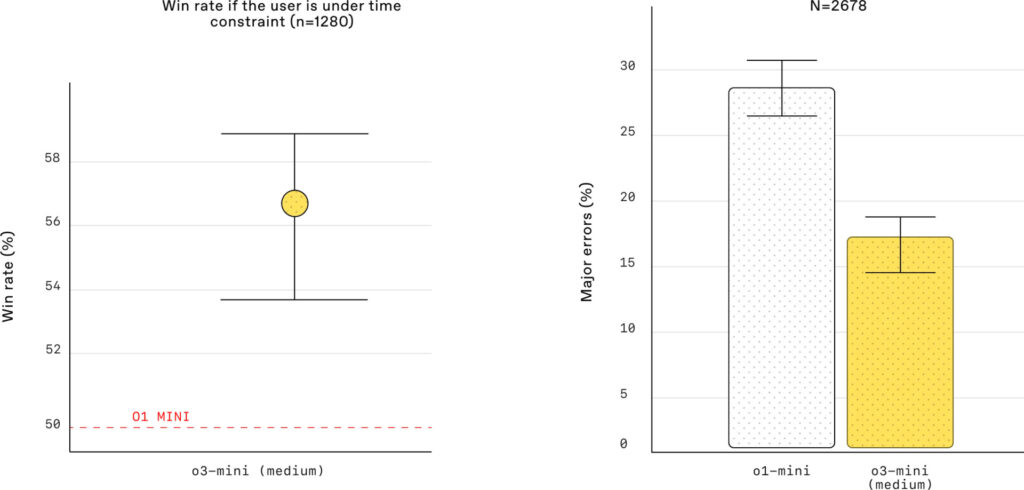
Pero la verdadera prueba de la velocidad de o3-mini se revela en las pruebas A/B. En estas pruebas comparativas, o3-mini entregó respuestas un 24% más rápido que o1-mini, con un tiempo de respuesta promedio de 7.7 segundos en comparación con los 10.16 segundos de o1-mini. Esta diferencia de tiempo puede parecer pequeña, pero en aplicaciones del mundo real, donde se generan miles o millones de respuestas, la mejora en la velocidad se traduce en un ahorro significativo de tiempo y recursos.
La latencia hasta el primer token

La imagen compara la latencia, específicamente el tiempo hasta el primer token (Time to first token), entre o1-mini y o3-mini (con un esfuerzo de razonamiento medio). Este tiempo, OpenAI lo ha considerado como crucial para la experiencia del usuario, ya que representa la rapidez con la que el modelo comienza a generar una respuesta.
Punto de reflexión: ¿Será porque hay mucha competencia? 🙂
El gráfico muestra claramente que o3-mini es significativamente más rápido que o1-mini. La barra amarilla, que representa o3-mini, es considerablemente más corta que la barra gris, que representa o1-mini. El eje horizontal indica el tiempo en milisegundos (ms).
El texto asociado a la imagen cuantifica esta diferencia: o3-mini tiene un tiempo hasta el primer token 2500 ms (2.5 segundos) más rápido que o1-mini. Esta reducción en la latencia es sustancial y se traduce en una experiencia de usuario mucho más fluida y receptiva.
En el contexto de aplicaciones interactivas, como chatbots o asistentes virtuales, esta mejora en la velocidad es fundamental. Un tiempo de respuesta más rápido significa que los usuarios perciben la IA como más ágil y «en tiempo real», lo que mejora la satisfacción y la usabilidad.
Punto de reflexión: Aquí se puede apreciar el porqué de mi pregunta anterior y es justificable.
Es importante recordar que esta comparación se realiza entre o3-mini con un esfuerzo de razonamiento medio y o1-mini. Considerando que o3-mini también ofrece mejoras en precisión y rendimiento en comparación con o1-mini, la reducción en la latencia se suma a las ventajas generales del nuevo modelo.
Priorizando la seguridad con «deliberative alignment»
Hasta ahora todas las pruebas van demostrando que OpenAI o3-mini se destaca por su rendimiento superior en razonamiento, velocidad y eficiencia. Sin embargo, un aspecto fundamental en el desarrollo de cualquier IA es la seguridad y aquí también OpenAI lo ha tenido en cuenta revelando las estrategias implementadas para garantizar que o3-mini sea un modelo seguro y confiable.
Una de las técnicas clave utilizadas para enseñar a o3-mini a responder de manera segura es el «deliberative alignment» (alineación deliberativa). Esta técnica consiste en entrenar al modelo para que razone sobre especificaciones de seguridad escritas por humanos antes de responder a las solicitudes de los usuarios. En otras palabras, o3-mini no solo busca la respuesta correcta, sino que también evalúa si esa respuesta cumple con los estándares de seguridad establecidos.
Al igual que con OpenAI o1, se ha encontrado que o3-mini supera significativamente a GPT-4 en evaluaciones desafiantes de seguridad y «jailbreak» (intentos de eludir las restricciones de seguridad). Esto demuestra la eficacia de las técnicas de seguridad implementadas en o3-mini y su capacidad para resistir intentos de manipulación maliciosa.
Antes de su implementación, se realizó una evaluación exhaustiva de los riesgos de seguridad de o3-mini, utilizando el mismo enfoque de preparación, «red-teaming» externo y evaluaciones de seguridad que se aplicó a o1. Este proceso riguroso garantiza que o3-mini haya sido sometido a pruebas exhaustivas para identificar y mitigar posibles vulnerabilidades.
Evaluaciones de contenidos no autorizados
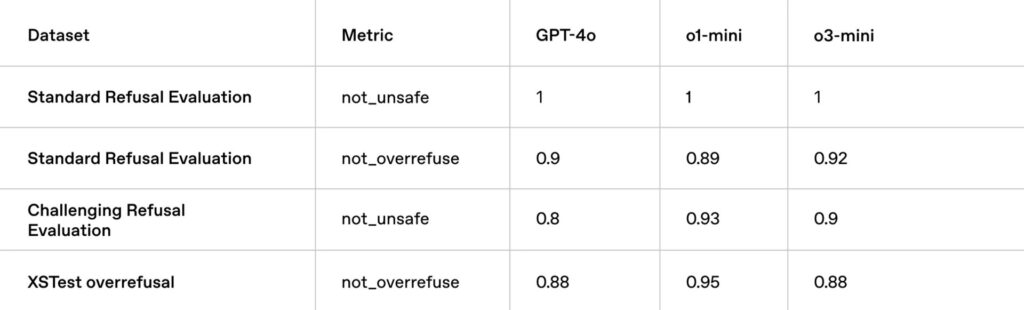
La tabla presenta cuatro evaluaciones diferentes, cada una enfocada en un aspecto distinto de la seguridad del modelo:
- Standard Refusal Evaluation (Evaluación de Rechazo Estándar):
- not_unsafe (no_inseguro): Evalúa la capacidad del modelo para evitar generar contenido inseguro o inapropiado.
- not_overrefuse (no_sobrerrechazar): Evalúa si el modelo rechaza solicitudes legítimas por error, lo que se conoce como «sobre-rechazo».
- Challenging Refusal Evaluation (Evaluación de Rechazo Desafiante):
- not_unsafe (no_inseguro): Similar a la evaluación estándar, pero con solicitudes más complejas y sutiles para evaluar la capacidad del modelo para detectar contenido inseguro en situaciones más difíciles.
- XSTest overrefusal (Sobrerrechazo de XSTest):
- not_overrefuse (no_sobrerrechazar): Evalúa específicamente el sobre-rechazo en el conjunto de datos XSTest, que contiene solicitudes diseñadas para ser ambiguas y poner a prueba la capacidad del modelo para distinguir entre solicitudes legítimas e inseguras.
Los resultados de la tabla muestran lo siguiente:
- GPT-4:
- En la Evaluación de Rechazo Estándar, obtiene la máxima puntuación (1) en «no_inseguro», lo que indica que evita generar contenido inseguro en situaciones estándar.
- En la misma evaluación, obtiene 0.9 en «no_sobrerrechazar», lo que sugiere que ocasionalmente puede sobre-rechazar solicitudes legítimas.
- En la Evaluación de Rechazo Desafiante, obtiene 0.8 en «no_inseguro», lo que indica que puede tener dificultades para detectar contenido inseguro en situaciones más complejas.
- En XSTest overrefusal, obtiene 0.88, lo que sugiere que también puede sobre-rechazar solicitudes legítimas en este conjunto de datos específico.
- o1-mini:
- En la Evaluación de Rechazo Estándar, obtiene la máxima puntuación (1) en «no_inseguro», similar a GPT-4.
- En la misma evaluación, obtiene 0.89 en «no_sobrerrechazar», un poco mejor que GPT-4.
- En la Evaluación de Rechazo Desafiante, obtiene 0.93 en «no_inseguro», superando a GPT-4 y mostrando una mayor capacidad para detectar contenido inseguro en situaciones complejas.
- En XSTest overrefusal, obtiene 0.95, superando también a GPT-4 en evitar el sobre-rechazo en este conjunto de datos.
- o3-mini:
- En la Evaluación de Rechazo Estándar, obtiene la máxima puntuación (1) en «no_inseguro», al igual que los otros modelos.
- En la misma evaluación, obtiene 0.92 en «no_sobrerrechazar», superando a GPT-4 y mejorando ligeramente a o1-mini.
- En la Evaluación de Rechazo Desafiante, obtiene 0.9 en «no_inseguro», superando a GPT-4 y acercándose al rendimiento de o1-mini.
- En XSTest overrefusal, obtiene 0.88, similar a GPT-4 pero ligeramente por debajo de o1-mini.
Evaluaciones sobre el enfoque Jailbreaks
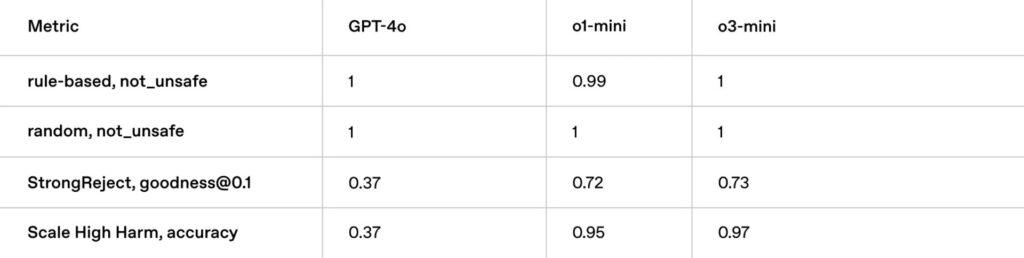
En este contexto, «Jailbreak» se refiere a la capacidad de un modelo de lenguaje para resistir intentos de manipulación o engaño que buscan que el modelo genere contenido dañino o inapropiado, incluso si va en contra de sus protocolos de seguridad.
La tabla presenta cuatro métricas diferentes, cada una enfocada en un aspecto distinto de la resistencia a «Jailbreak»:
- rule-based, not_unsafe: Evalúa la capacidad del modelo para evitar generar contenido inseguro o inapropiado cuando se le dan instrucciones basadas en reglas.
- random, not_unsafe: Similar a la evaluación anterior, pero con instrucciones aleatorias para evaluar la capacidad del modelo para detectar contenido inseguro en situaciones no estructuradas.
- StrongReject, goodness@0.1: Evalúa la capacidad del modelo para rechazar solicitudes maliciosas o inapropiadas con un alto grado de confianza (0.1).
- Scale High Harm, accuracy: Evalúa la precisión del modelo para identificar y evitar contenido que pueda causar daño a gran escala.
Los resultados de la tabla muestran lo siguiente:
- GPT-4o:
- En «rule-based, not_unsafe», obtiene la máxima puntuación (1), lo que indica que evita generar contenido inseguro cuando se le dan instrucciones basadas en reglas.
- En «random, not_unsafe», también obtiene la máxima puntuación (1), lo que sugiere que es bueno para detectar contenido inseguro en situaciones no estructuradas.
- En «StrongReject, goodness@0.1», obtiene 0.37, lo que indica que tiene dificultades para rechazar solicitudes maliciosas con alta confianza.
- En «Scale High Harm, accuracy», también obtiene 0.37, lo que sugiere que tiene dificultades para identificar y evitar contenido dañino a gran escala.
- o1-mini:
- En «rule-based, not_unsafe», obtiene 0.99, lo que indica que es casi perfecto para evitar contenido inseguro con instrucciones basadas en reglas.
- En «random, not_unsafe», obtiene la máxima puntuación (1), similar a GPT-4o.
- En «StrongReject, goodness@0.1», obtiene 0.72, superando a GPT-4o y mostrando una mayor capacidad para rechazar solicitudes maliciosas con alta confianza.
- En «Scale High Harm, accuracy», obtiene 0.95, superando también a GPT-4o y mostrando una mayor precisión para evitar contenido dañino a gran escala.
- o3-mini:
- En «rule-based, not_unsafe», obtiene la máxima puntuación (1), al igual que los otros modelos.
- En «random, not_unsafe», también obtiene la máxima puntuación (1), similar a GPT-4o y o1-mini.
- En «StrongReject, goodness@0.1», obtiene 0.73, similar a o1-mini y superando a GPT-4o.
- En «Scale High Harm, accuracy», obtiene 0.97, superando a GPT-4o y o1-mini, lo que indica una mayor precisión para evitar contenido dañino a gran escala.
Conclusión acerca de las pruebas hechas sobre el modelo “o3-mini”
OpenAI demuestra la serie de pruebas realizadas con el fin de explorar en detalle las capacidades de OpenAI “o3-mini”, aplicando diversas técnicas y métricas dependiendo del objeto de prueba, destacando su rendimiento superior en razonamiento, velocidad, eficiencia y seguridad.
Varios fueron sus objetos de prueba comparándolos con los modelos anteriores para poder demostrar su rendimiento superior. El listado que te presento a continuación te muestra el objeto de prueba y las métricas evaluadas:
- AIME
- GPQA
- FrontierMath [Pass@1, Pass@4 y Pass@8]
- Codeforces [ELO]
- SWE-bench Verified [Precisión]
- LiveBench Coding [Average (Promedio), LCB Generation (Generación de LCB) y Code Completion (Finalización de Código)]
- Capacidad de conocimiento general [MMLU (pass@1), Math (pass@1), MGSM (pass@1), SimpleQA]
- Preferencias humanas [STEM, Non STEM]
- Latencia [Time to first token]
- Evaluaciones de contenidos no autorizados [not_unsafe y not_overrefuse]
- Jailbreak [rule-based, not_unsafe; random, not_unsafe; StrongReject, goodness@0.1; Scale High Harm, accuracy]
El lanzamiento del modelo “o3-mini” representa un avance significativo en la misión de OpenAI de ampliar los límites de la inteligencia rentable. Al optimizar el razonamiento para dominios STEM y mantener los costos bajos, OpenAI está democratizando el acceso a una IA de alta calidad. O3-mini no es solo un modelo potente, sino también accesible, lo que permite que más personas y organizaciones se beneficien de sus capacidades. De aquí a que se haya considerado el concepto de asequibilidad.
Este modelo continúa la trayectoria de OpenAI de reducir el costo de la inteligencia. El texto menciona una reducción del 95% en el precio por token desde el lanzamiento de GPT-4, lo que demuestra el compromiso de la empresa con la accesibilidad. A pesar de esta drástica reducción de costos, o3-mini mantiene capacidades de razonamiento de primer nivel, lo que subraya que la accesibilidad no compromete la calidad.
A medida que la adopción de la IA se expande, OpenAI se compromete a liderar en la vanguardia, construyendo modelos que equilibren inteligencia, eficiencia y seguridad a escala. O3-mini es un ejemplo perfecto de este equilibrio, ofreciendo un rendimiento excepcional en un paquete eficiente y seguro.
En resumen, OpenAI o3-mini no es solo un modelo avanzado, sino también un paso importante hacia un futuro donde la IA es más accesible, inteligente y segura. La combinación de capacidades de razonamiento de alto nivel, eficiencia en costos y un enfoque en la seguridad demuestra el compromiso de OpenAI con la creación de tecnología que beneficie a la sociedad en su conjunto. La visión de OpenAI de democratizar el acceso a la IA de alta calidad se materializa con modelos como o3-mini, que abren un abanico de posibilidades para innovar y resolver problemas complejos en diversos campos.
Punto de reflexión: Me caben varias preguntas entre ellas: ¿Cuán democráticos son sus diferentes modelos? ¿No he visto aún, y tal vez lo he pasado por alto, pruebas que tengan que ver con la energía que se requiere para el procesamiento de toda esta información considerando que el primer modelo requería un cierto nivel de procesamiento y estos últimos seguramente necesitarán más potencia de procesamiento? ¿Cuánto es el impacto que este aspecto tiene en nuestro planeta?
Fuente de inspiración: OpenAI

{kind=link}