
Entrando en tema
RAG, o Generación Aumentada por Recuperación, es un enfoque arquitectónico que mejora las respuestas de los Modelos de Lenguaje Grandes (LLM, por sus siglas en inglés) al permitirles acceder e integrar información de bases de datos externas. En lugar de depender únicamente de la información pre-aprendida en el LLM, RAG recupera contexto adicional relevante de fuentes externas para enriquecer y hacer más específicas, contextuales y profundas sus respuestas. Esto ayuda a mitigar problemas como las «alucinaciones» (donde el LLM genera información incorrecta o inventada) y la falta de actualidad de los datos. La idea central de RAG es aumentar la respuesta del LLM extrayendo información contextual relevante para enriquecer el resultado a la petición del usuario.
Ahora sí, profundicemos
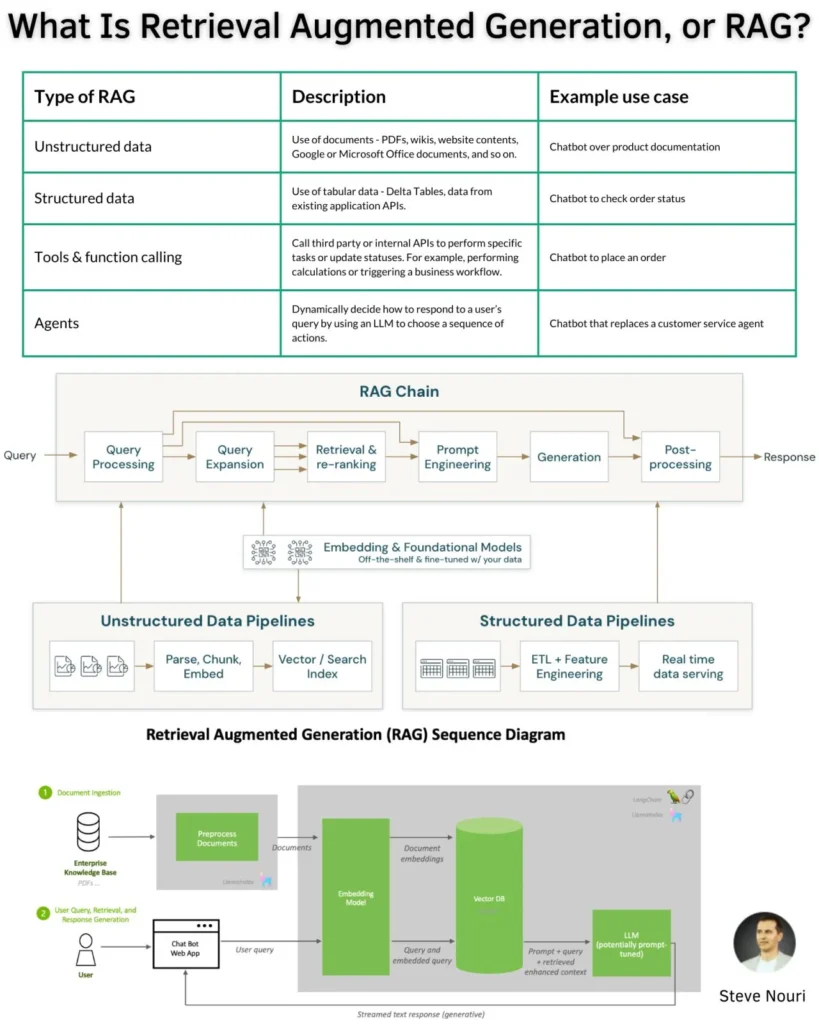
Los sistemas RAG se han convertido en una parte fundamental del desarrollo de aplicaciones empresariales de LLM, ya que permiten a estos modelos aumentar sus capacidades creativas y técnicas. La implementación de un sistema RAG implica varias etapas y consideraciones técnicas importantes:
¿Cómo funciona un sistema RAG básico?
- Preparación de datos (Fase de documentos): Los documentos y textos externos que conforman tu base de datos se convierten en un formato matemático llamado «vectores» mediante un «codificador» o modelo de embeddings. Estos vectores capturan el significado semántico del texto y se almacenan en una «base de datos de vectores». Esta etapa es fundamental para el LLM pueda «entender» los datos.
- Fase de recuperación: Cuando un usuario hace una consulta, esta se codifica en un vector utilizando el mismo modelo que se usó para la base de datos externa. Este vector de consulta se compara con los vectores almacenados en la base de datos de vectores para encontrar los documentos más similares o relevantes. Por ejemplo, se pueden recuperar los cinco documentos principales.
- Fase de generación (aumento y generación): La consulta del usuario y los documentos recuperados se combinan para crear un contexto enriquecido que alimenta al LLM. El LLM utiliza este contexto aumentado (en lugar de solo su conocimiento pre aprendido) para generar una respuesta más específica, contextual y precisa. Además, el sistema puede proporcionar enlaces o atribuciones a las fuentes originales para verificar la exactitud de la información.
Requerimientos técnicos para implementar sistemas RAGs
La construcción de un sistema RAG empresarial robusto implica la integración y optimización de varios componentes técnicos:
- Técnicas de Chunking (dividir en fragmentos): Antes de crear embeddings, los documentos largos deben dividirse en «chunks» o fragmentos más pequeños y manejables. Esto mejora la calidad de recuperación, optimiza el almacenamiento y el costo. Los factores que influyen en la estrategia de chunking incluyen la estructura del texto (oraciones, párrafos, código, tablas), el modelo de embedding, la longitud del contexto del LLM y el tipo de preguntas. Algunas técnicas comunes son:
- Divisor de caracteres: Versátil y flexible, pero puede cortar oraciones.
- Divisor de caracteres recursivo: Similar al anterior, pero con un enfoque recursivo.
- Divisor de oraciones: Considera los límites de las oraciones, evitando cortes prematuros.
- Divisor semántico: Agrupa texto basándose en la similitud semántica, útil para contextos caóticos.
- Proposiciones: Unidades atómicas de significado, auto-contenidas y mínimas, que encapsulan un hecho distinto.
- Chunking basado en LLM: Se pueden usar LLMs para generar chunks o proposiciones.
- Modelos de Embedding: Estos modelos convierten los «chunks» de texto en representaciones numéricas de alta dimensión (vectores) que capturan su significado semántico. La elección del modelo de embedding es crucial para el éxito del sistema RAG. Los tipos de modelos que hoy conocemos son:
- Embeddings densos: Vectores continuos de valores reales en un espacio de alta dimensión, ideales para capturar el significado semántico general.
- Embeddings dispersos: Vectores con la mayoría de los valores en cero, que enfatizan solo la información relevante, útiles para terminologías raras.
- Embeddings multi-vectoriales (late interaction): Codifican consultas y documentos de forma independiente, seguida de un paso de interacción ligero.
- Embeddings de contexto largo: Permiten codificar secuencias de hasta 8192 tokens o más, reduciendo la fragmentación semántica.
- Embeddings de dimensión variable (matryoshka representation learning – MRC): Aprenden embeddings de baja dimensión anidados dentro de embeddings originales.
- Embeddings de código: Integran capacidades de IA en entornos de desarrollo al entender la intención detrás de las consultas relacionadas con código.
- Bases de datos de vectores: Una vez generados, los embeddings se almacenan en una base de datos de vectores, optimizada para almacenar, indexar y consultar eficientemente vectores de alta dimensión. Esto permite búsquedas de similitud rápidas
- Técnicas de re-ranking (reordenamiento): Después de la recuperación inicial, los rerankers reordenan los documentos recuperados para priorizar los más relevantes para la consulta del usuario. Esto es crucial para manejar contextos irrelevantes y reducir las alucinaciones del LLM. Existen diferentes enfoques:
- Métodos puntuales: Miden la relevancia entre una consulta y un solo documento.
- Métodos de lista: Reordenan una lista completa de documentos.
- Métodos de pares: Comparan documentos en pares para determinar cuál es más relevante.
- Rerankers supervisados basados en LLMs: LLMs ajustados en conjuntos de datos de clasificación para medir la relevancia consulta-documento.
- Rerankers no supervisados basados en LLMs: Utilizan LLMs para mejorar el reordenamiento de documentos de forma autónoma, a través de prompting.
- Herramientas de Orquestación: Herramientas como Langchain o LlamaIndex («Langchain/Llamaindex/DSL») se utilizan para gestionar el flujo de trabajo y las interacciones entre los diferentes componentes de un sistema RAG.
- Generador (LLM): Es el corazón del sistema, responsable de generar la respuesta final. Puede ser un modelo alojado en la nube (a través de una API como OpenAI, Anthropic, Cohere, etc.) o un modelo autoalojado. Las consideraciones incluyen el rendimiento (paralelismo de tensores, procesamiento por lotes continuo, cuantificación), y las funcionalidades que mejoran la calidad de la generación (procesamiento de logits, escalado de temperatura, top-p, top-k, penalización por repetición, secuencias de detención, probabilidades de log).
Precondiciones a tener en cuenta (desafíos y consideraciones empresariales): Al implementar RAG, es importante considerar varios desafíos y aspectos empresariales para asegurar su robustez y eficiencia:
- Problema de las Alucinaciones: Aunque RAG reduce significativamente las alucinaciones al fundamentar las respuestas en evidencia recuperada, un contexto excesivo o irrelevante aún puede inducir alucinaciones.
- Actualidad de la Información: RAG supera el problema de la información «obsoleta» de los LLMs al permitir la actualización continua de la base de datos externa, lo que se refleja en las respuestas del LLM.
- Desafíos comunes en RAG:
- Contenido perdido: Cuando los documentos disponibles no pueden responder a la pregunta.
- Documentos no en contexto: Los documentos recuperados no se ajustan al contexto de la pregunta, a menudo debido a límites de tokens del LLM que truncan la información relevante.
- Fallo de extracción: El LLM no puede extraer la información correcta de un contexto que sí la contiene, comúnmente por ruido o información contradictoria.
- Adherencia al formato: El modelo ignora las instrucciones para dar una respuesta en un formato específico.
- Respuestas genéricas/vagas: La consulta es ambigua y el LLM da una respuesta genérica o arroja demasiada información.
- Velocidad de recuperación: Los sistemas RAG pueden ser más lentos que los LLM estándar, requiriendo optimización.
- Seguridad: La base de datos externa puede ser envenenada con información errónea por ataques externos, afectando las respuestas del LLM.
- Consideraciones de costo y latencia: La capacidad de los LLM tiene un costo considerable. Los chunks grandes pueden aumentar la latencia y los costos de servicio, mientras que los chunks más pequeños pueden reducir el contexto. El reordenamiento también puede aumentar la latencia debido a la sobrecarga computacional. La elección entre el rendimiento y el costo es un equilibrio importante.
- Características empresariales:
- Cumplimiento normativo: Asegurar que la base de datos de vectores cumpla con estándares de la industria como SOC-2, GDPR y HIPAA.
- Inicio de sesión único (SSO): Integración con proveedores de identidad (Google, Microsoft, Okta) para una gestión de acceso simplificada.
- Límites de tasa: Establecer umbrales para prevenir sobrecargas del sistema y priorizar tareas críticas.
- Multi-tenencia: Permitir que múltiples usuarios o clientes compartan una única instancia de base de datos de forma eficiente y aislada.
- Control de acceso basado en roles (RBAC): Definir privilegios y permisos basados en los roles de los usuarios para la seguridad de los datos.
- Guardrails de entrada: Mecanismos para detectar inyecciones de prompts dañinos o manipuladores, limitar tokens de entrada y detectar toxicidad en las consultas del usuario.
- Guardrails de salida: Similares a los de entrada, pero enfocados en detectar alucinaciones, menciones de competidores y posibles daños a la marca en las respuestas generadas.
Importancia de tener elaboradas previamente técnicas de prompting
Las técnicas de prompting son fundamentales para guiar el comportamiento del LLM y mejorar la calidad de sus respuestas en un sistema RAG, especialmente para reducir las alucinaciones. Algunas de las técnicas clave incluyen:
- Chain of Thought (CoT – Cadena de Pensamiento): Guía al modelo a través de ejemplos para que imite una secuencia lógica de pasos para llegar a una respuesta. Esto ayuda al LLM a razonar mejor y dar respuestas más correctas, especialmente en problemas complejos. Sin embargo, si un paso es defectuoso, el error se propaga.
- Thread of Thought (ThoT – Hilo de Pensamiento): Útil cuando el contexto recuperado es «caótico» o desorganizado. Instruye al modelo a ir paso a paso, resumir y analizar cada paso para extraer los detalles esenciales para responder a la consulta con precisión. Es más flexible que CoT para información compleja.
- Chain of Note (CoN – Cadena de Notas): Aborda el problema de la sobre-dependencia de los documentos recuperados o la dificultad para manejar información contradictoria. El modelo genera «notas de lectura» concisas y relevantes a partir de los documentos recuperados, y luego utiliza estas notas para sintetizar la respuesta final.
- Chain of Verification (CoVe – Cadena de Verificación): Genera preguntas de verificación a partir de una respuesta inicial del LLM. Luego, busca evidencia para responder a estas preguntas de verificación y, basándose en la evidencia de apoyo o contradictoria, revisa y mejora la respuesta inicial. Esto mejora la precisión y profundidad de la respuesta.
- EmotionPrompt (Prompt Emocional): Introduce señales emocionales en el prompt para mejorar el rendimiento del modelo. Al transmitir pensamientos, sentimientos y estado emocional junto con la consulta, se busca que el modelo procese la solicitud de manera más efectiva.
- ExpertPrompt (Prompt de Experto): Instruye al LLM a asumir la identidad de un experto en un campo específico (por ejemplo, «Imagina que eres un abogado experto…») para obtener respuestas más detalladas y matizadas. Esto aprovecha el potencial del LLM para responder como especialistas distinguidos.
Estas técnicas, a menudo pasadas por alto, son vitales para guiar al LLM y mejorar drásticamente sus respuestas. También se pueden usar en conjunto con RAG y el fine-tuning para refinar aún más las respuestas de los LLM, similar a estudiar un libro de texto antes de un examen a libro abierto.
Cuánto por leer, analizar, sintetizar, investigar, codificar, asimilar, comparar, automatizar, pensar, imaginar, tratar, discutir, evaluar, probar, refinar, complementar, y volver a empezar ¿cierto?
Fuente de inspiración: Mastering RAG by Galileo (www.rungalileo.io), https://www.linkedin.com/in/stevenouri/

{kind=link}